

Many production systems are a collection of loosely coupled services that communicate with each other using messages or events. The distributed nature of these systems makes reliability and correctness challenging. Lost messages or duplicate processing cause bugs ranging from minor annoyances to disastrous outages.
One surprisingly effective solution for implementing a messaging service is to "just use Postgres" (especially for applications that already use it to store data). Its strong transactional guarantees allow you to both send and consume messages exactly-once, making it easier to build highly reliable systems.
In this post, we’ll develop this idea: how Postgres simplifies the deployment of reliable messaging. We'll describe how to implement notifications as a Postgres table, how to perform atomic messaging, how to use LISTEN/NOTIFY to improve performance, and finally how to ensure applications never miss a single notification.
Storing notifications in Postgres
To build notifications in Postgres, you can make each message a row in a Postgres table. Here’s what such a table would look like:

Each message, uniquely identified by an ID, is produced for the consumption of a unique recipient, also identified by an ID. Topics are a nice-to-have metadata column that helps categorize communications. To send a message, write a row; to consume, read the row and flip the “consumed” column.
The reason this design is powerful is that it allows you to provide exactly-once semantics for sending and consuming methods, helping solve difficult production challenges like atomic workflows and duplicate messages.
Atomic messaging
Messages are often part of multi-step workflows that must run atomically. For example, an application handling payments might update inventory, process payments, then use messaging to trigger a shipment. These workflows must be atomic, that is, either all the steps complete, or none do. This prevents inconsistencies between systems, e.g., not shipping an item that was paid for. With notifications stored in a Postgres table, workflows can write messages exactly-once, as part of a larger transaction.
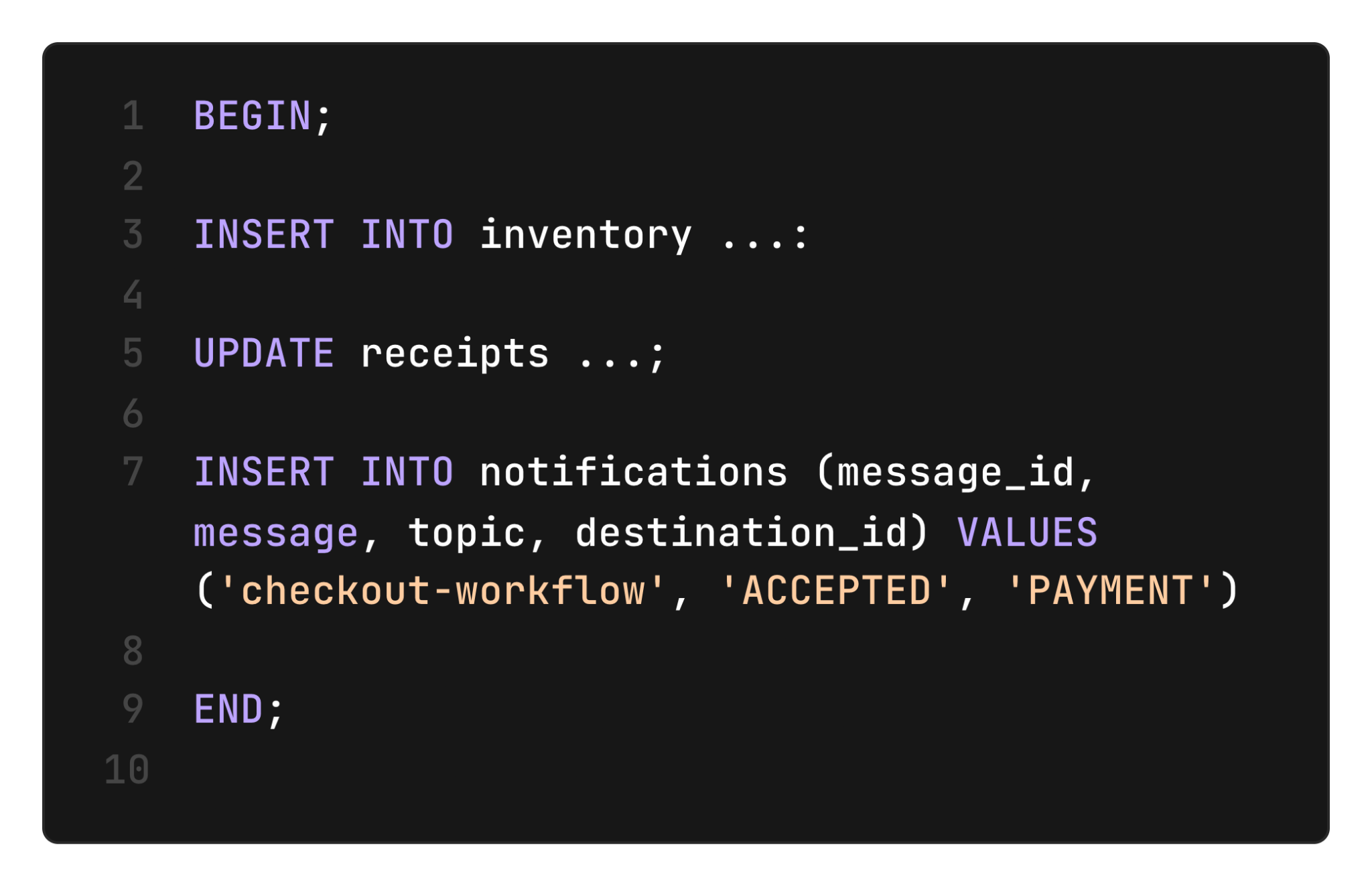
On the receiving side, we can also guarantee that the message is consumed atomically with other business logic, for example, scheduling a shipment:
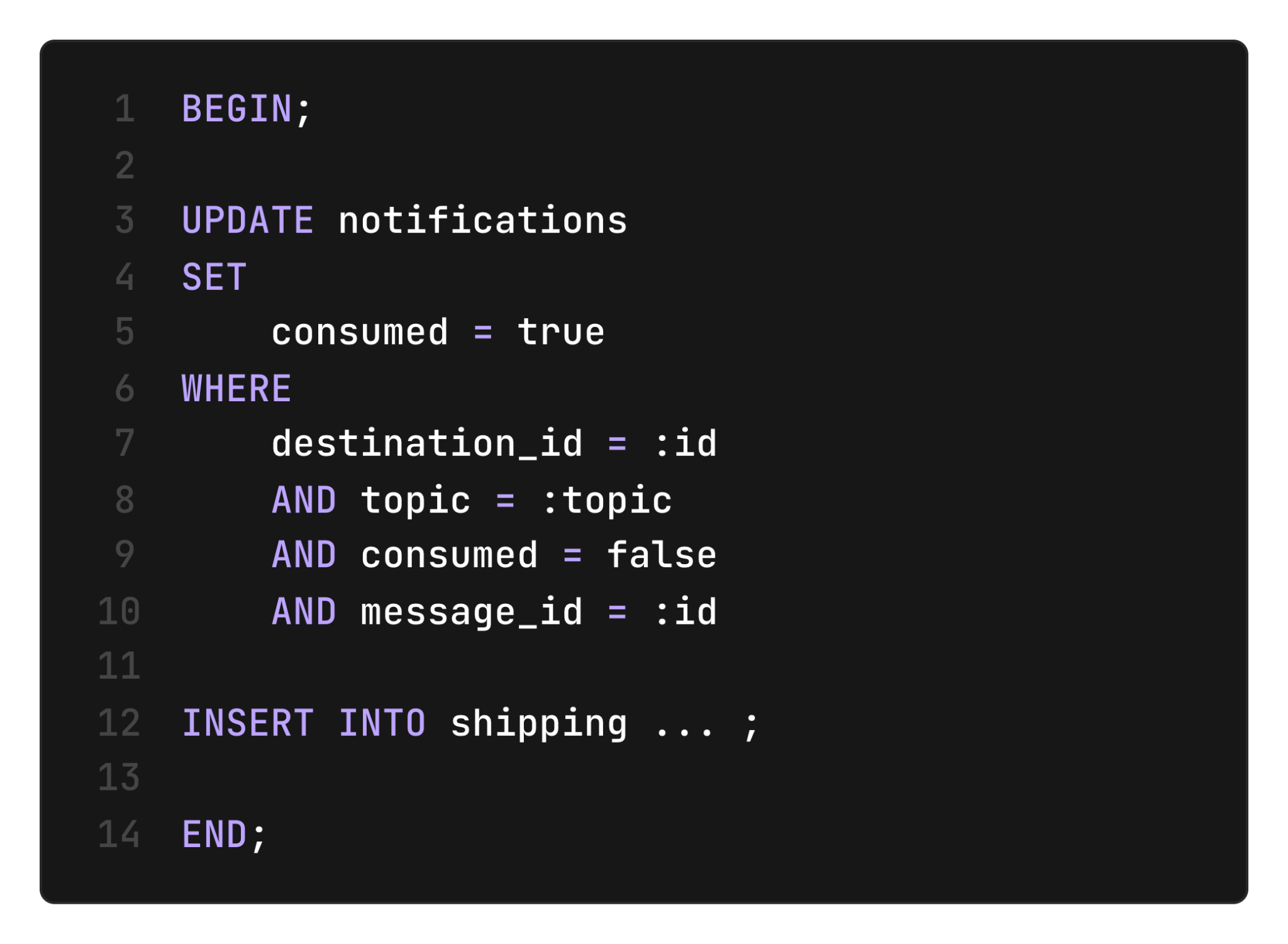
If the consumer process crashes after consuming the message but before scheduling the shipment, the message will remain marked as “unconsumed,” and a recovery worker will be able to pick up the work.
Duplicate messages
Duplicate messaging is a common problem in distributed architectures, for example when multiple workers can generate notifications about the same event. Duplicate messaging can lead to duplicate work, which at best wastes computing resources and at worst creates inconsistencies and bugs.
Storing notifications in a Postgres table allows us to handle concurrent execution out of the box. We leverage the unique constraint on the message ID as an idempotency key. When multiple workers attempt to insert the same message in the table, only one will be inserted into the database.
This extends to duplicate consumption. In a distributed setup, even with unique destination IDs, who knows if two processes won't run with the same ID and attempt to consume a message? By consuming messages exactly-once, we ensure that just one of these processes will read the message and perform the work associated with it.
Efficient and low-latency messaging
One challenge with storing notifications in Postgres is that consumers don’t know ahead of time when a new notification arrives. The obvious solution is to periodically poll the database to check for new messages, however this scales poorly as the number of consumers increase. Increasing the polling interval trades database load for poor application responsiveness.
We can address this challenge by leveraging Postgres’ LISTEN/NOTIFY. This feature allows Postgres clients to subscribe to notifications, which are emitted when a new message is written to the notifications table. That way, consumers do not need to poll the database, but are instead awakened when a new message is available.
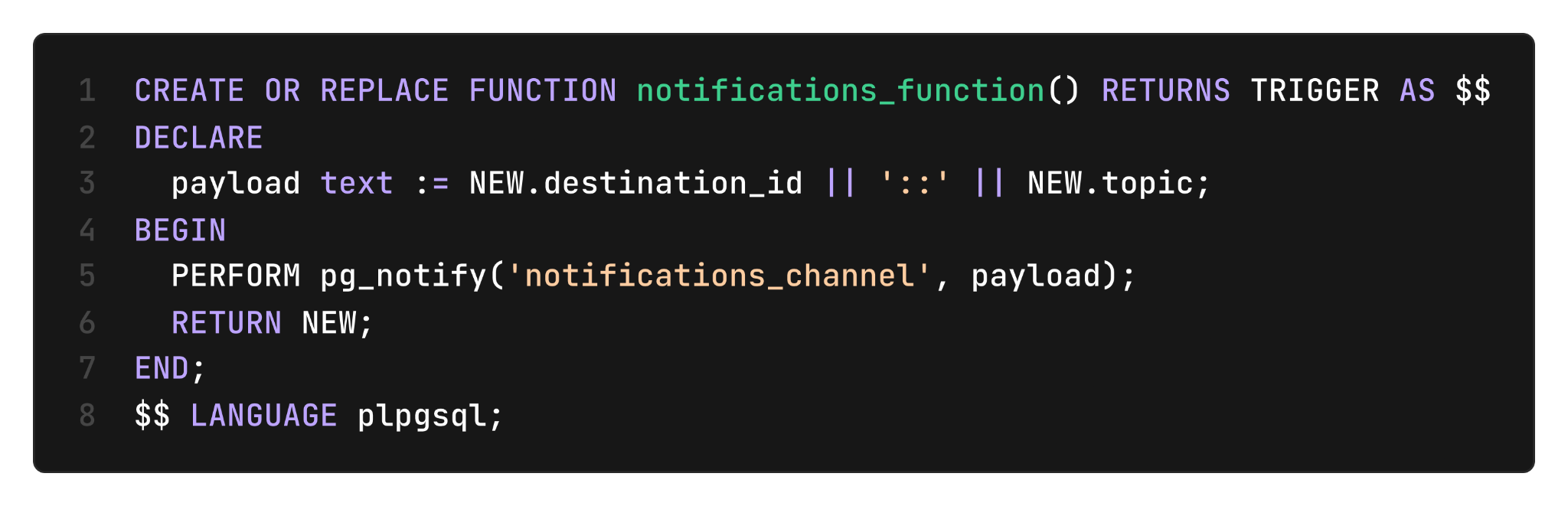
To use LISTEN/NOTIFY, we first install a trigger function that fires every time a new message is inserted in the notifications table:
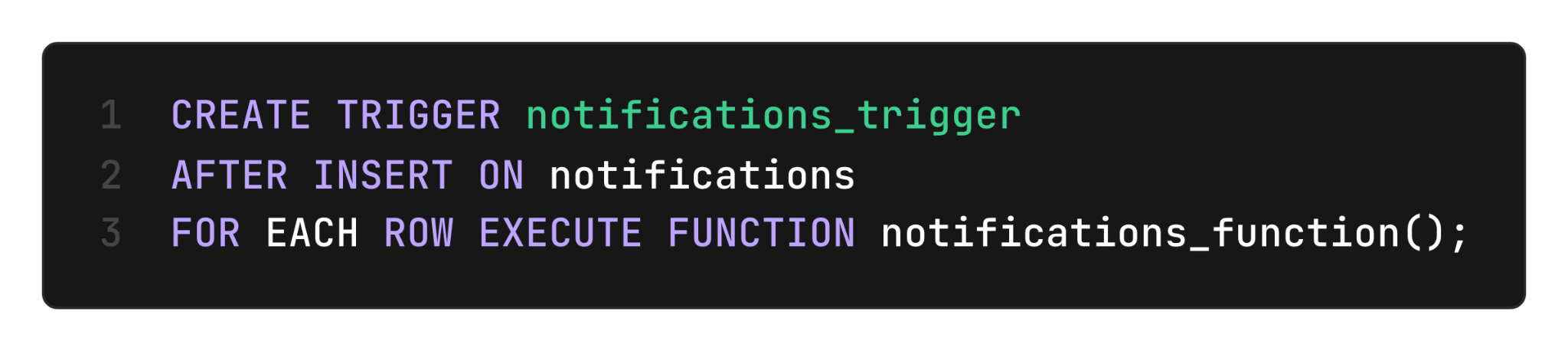
This trigger executes in the same transaction that inserts the notification. The trigger function calls pg_notify with a payload embedding both the destination ID and a topic.
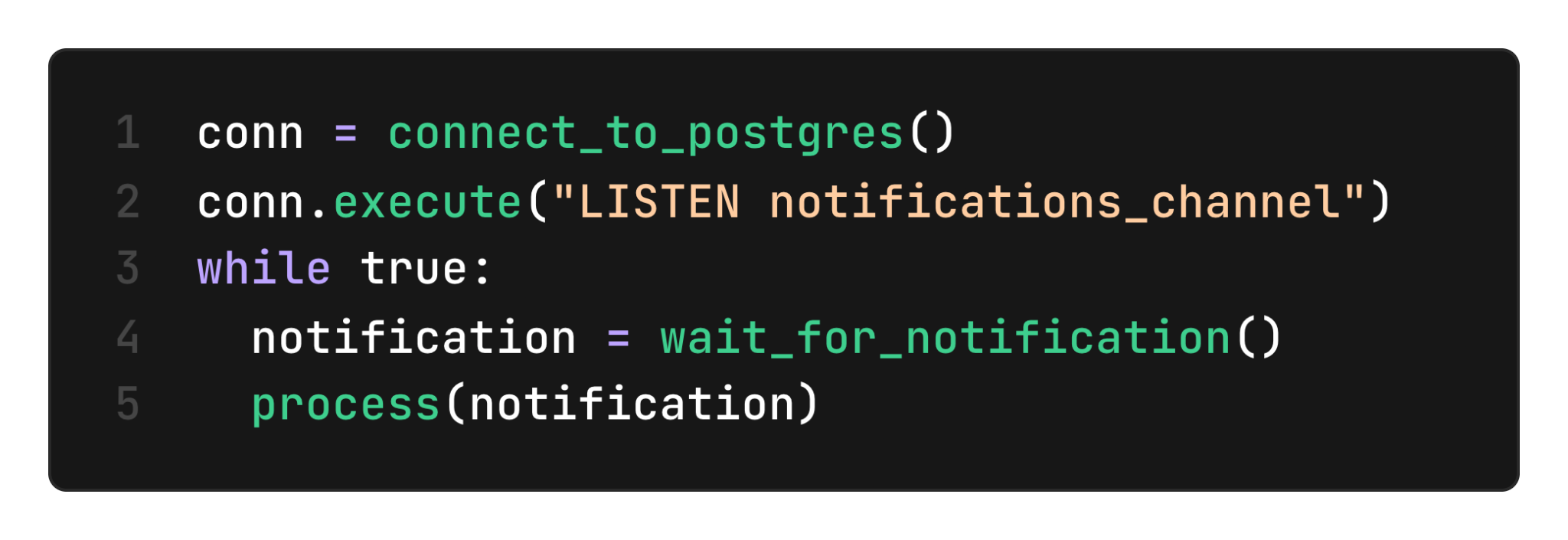
On the application layer, we need to open a connection that listens for notifications (executing LISTEN notifications_channel on a dedicated connection). Here is a simple example of a loop waiting for notifications and parsing their payload:
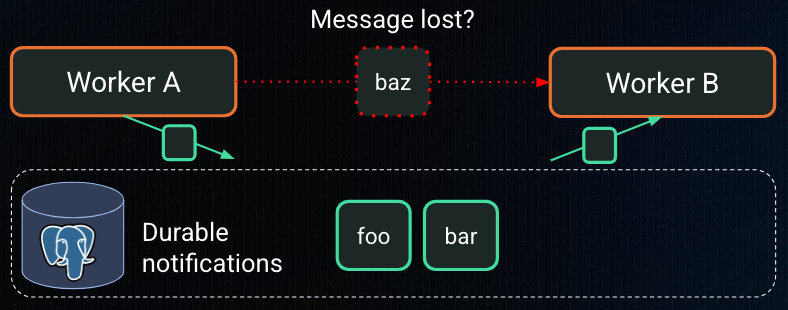
How to not miss any notifications
However, there is one crucial challenge for making this system reliable: there is a possibility that notifications are lost when the consumer’s connection is severed. Consider the following sequence of events:
- Insertion to the notifications table triggers pg_notify
- Consumer’s subscription connection to Postgres is severed, after pg_notify is called but before the signal has made it out of the Postgres server
- Consumers detect the connection issue, and re-creates a connection.
At the end of this sequence, the consumer will have lost the notification.
The solution is to explicitly catch connection errors and, in addition to creating a new LISTEN connection, query the notifications table, once, whenever we detect that the connection is severed. This ensures that even if we lost a notification while we were disconnected, we'll see the new message when we reconnect. Here is an example of what it looks like at the application level:
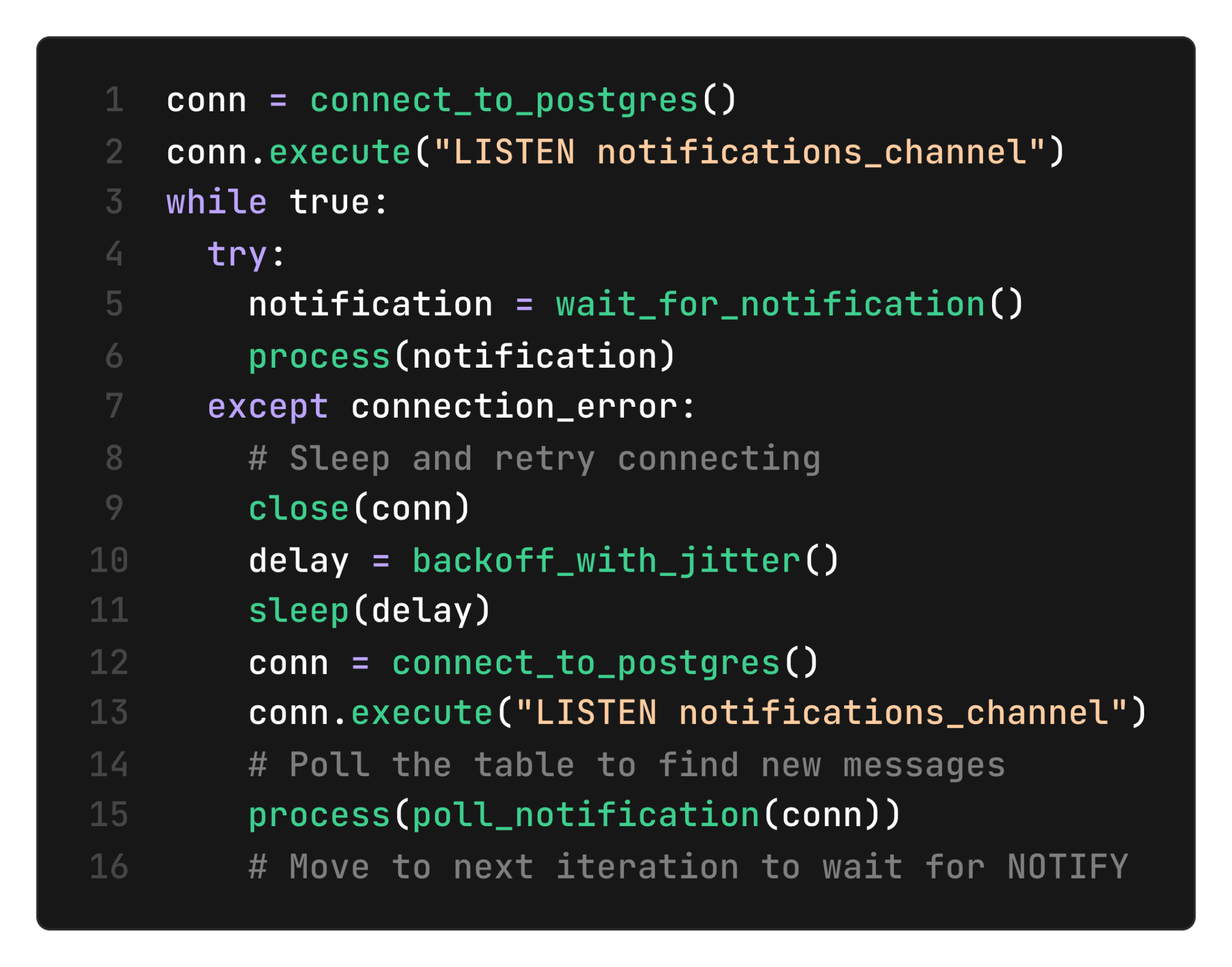
Briefly pausing before attempting to re-acquire the connection is important. It can otherwise lead to cascading failures if the database is overwhelmed by new connection attempts. A simple policy is to retry with exponential backoff; that is, slow down retries (up to a limit) when multiple attempts to re-acquire the connection fail.
Further, adding a random time interval (“jitter”) to the delay between retries is critical for stability in a distributed setup: a large enough number of consumers, all attempting to reconnect at the same time (regardless of the delay between attempts) can cause a “thundering herd” that will overwhelm the database.
Learn more
This is how we built a reliable and efficient notification system using Postgres. If you appreciate reliable systems, we’d love to hear from you. At DBOS, our goal is to make durable workflows as easy to work with as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67



