






When adding async support to our Python durable execution library, we ran into a fundamental challenge: durable workflows must be deterministic to enable replay-based recovery.
Making async Python workflows deterministic is difficult because they often run many steps concurrently. For example, a common pattern is to start many concurrent steps and use asyncio.gather to collect the results:
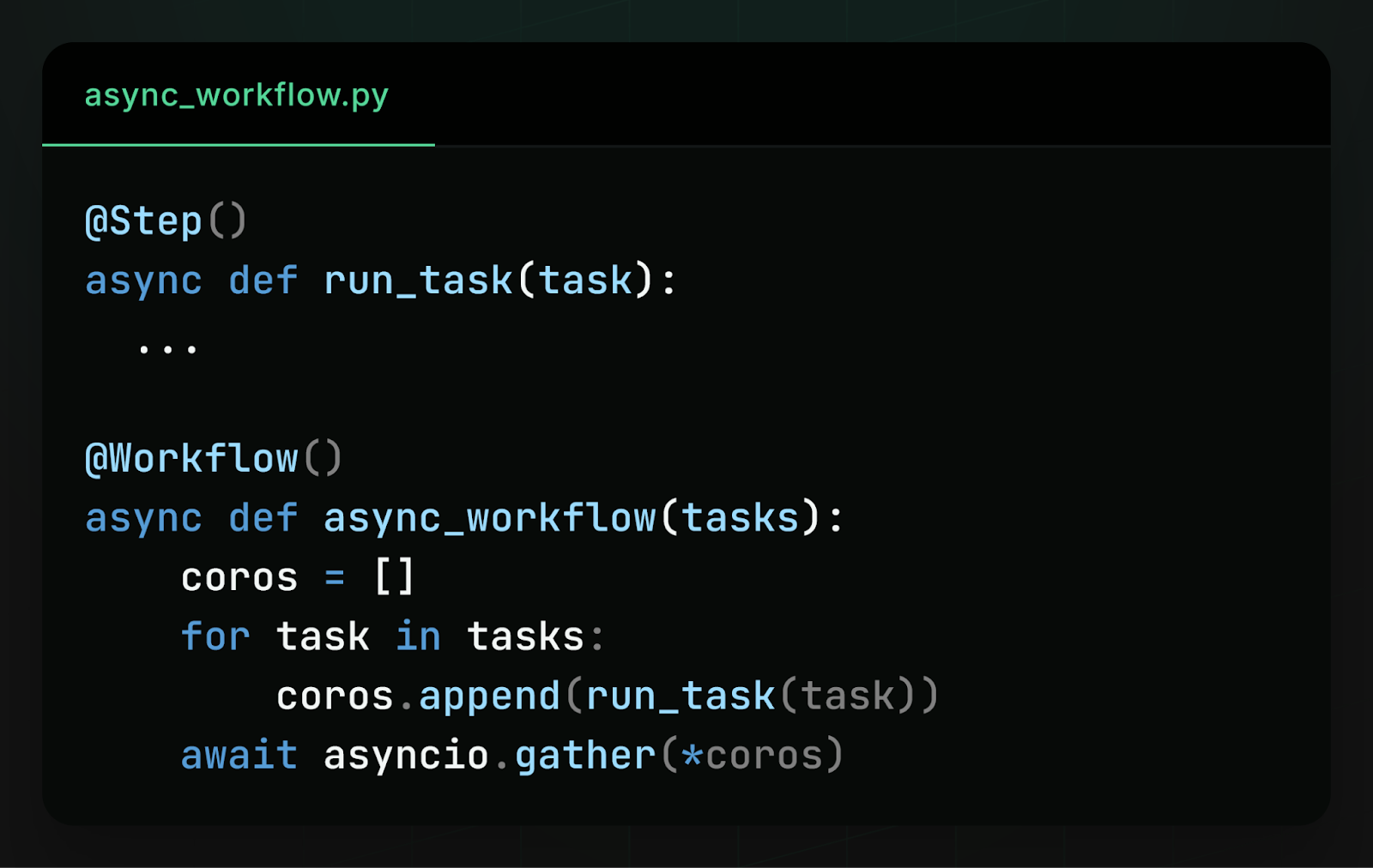
This is great for performance (assuming tasks are I/O-bound) as the workflow doesn’t have to wait for one step to complete before starting the next. But it’s not easy to order the workflow’s steps because those steps all run at the same time, with their executions overlapping, and they can complete in any order.
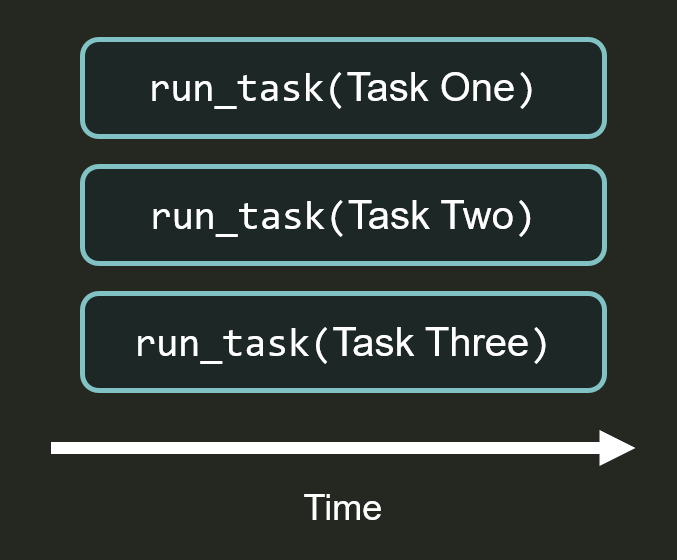
The problem is that concurrency introduces non-obvious step execution ordering. When multiple tasks run at the same time, the exact interleaving of their execution can vary. But during recovery, the workflow must be able to replay those steps deterministically, recovering completed steps from checkpoints and re-executing incomplete steps. This requires a well-defined step order that’s consistent across workflow executions.
So how do we get the best of both worlds? We want workflows that can execute steps concurrently, but still produce a deterministic execution order that can be replayed correctly during recovery. To make that possible, we need to better understand how the async Python event loop really works.
How Async Python Works
At the core of async Python is an event loop. Essentially, this is a single thread running a scheduler that executes a queue of tasks. When you call an async function, it doesn’t actually run; instead it creates a “coroutine,” a frozen function call that does not execute. To actually run an async function, you have to either await it directly (which immediately executes it, precluding concurrency) or create an async task for it (using asyncio.create_task or asyncio.gather), which schedules it on the event loop’s queue. The most common way to run many async functions concurrently is asyncio.gather, which takes in a list of coroutines, schedules each as a task, then waits for them all to complete.
Even after you schedule an async function by creating a task for it, it still doesn’t execute immediately. That’s because the event loop is single-threaded: it can only run one task at a time. For a new task to run, the current task has to yield control back to the event loop by calling await on something that isn’t ready yet. As tasks yield control, the event loop scheduler works its way through the queue, running each task sequentially until it itself yields control. When an awaited operation completes, the task awaiting it is placed back in the queue to resume where it left off.
Critically, the event loop schedules newly created tasks in FIFO order. Let’s say a list of coroutines is passed into asyncio.gather as in the code snippet above. asyncio.gather wraps each coroutine in a task, scheduling them for execution, then yields control back to the event loop. The event loop then dequeues the task created from the first coroutine passed into asyncio.gather and runs it until it yields control. Then, the event loop dequeues the second task, then the third, and so on.The order of execution after that is completely unpredictable and depends on what the tasks are actually doing, but tasks start in a deterministic order:
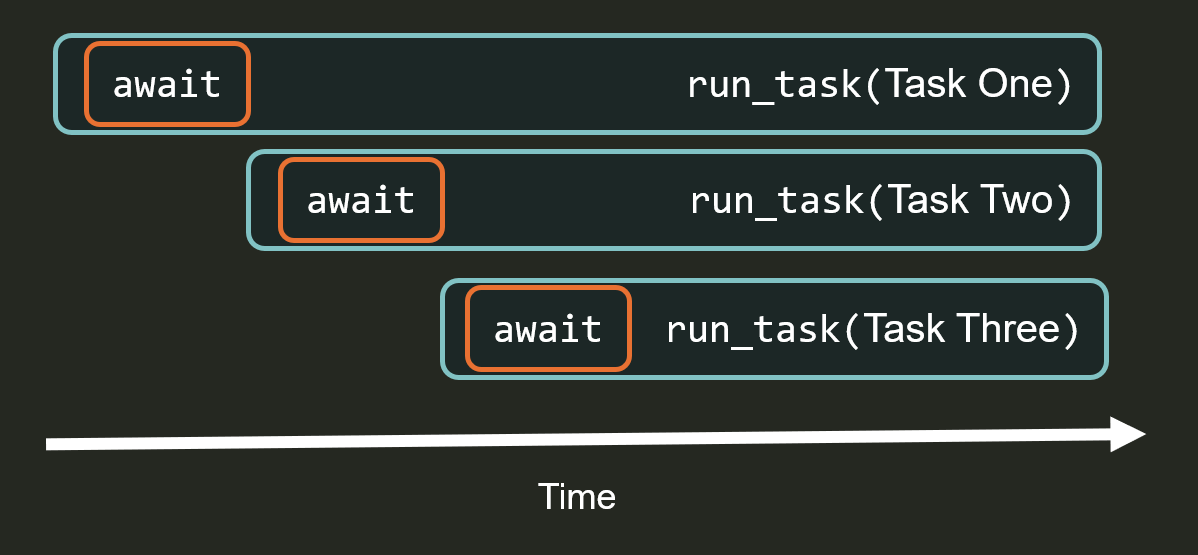
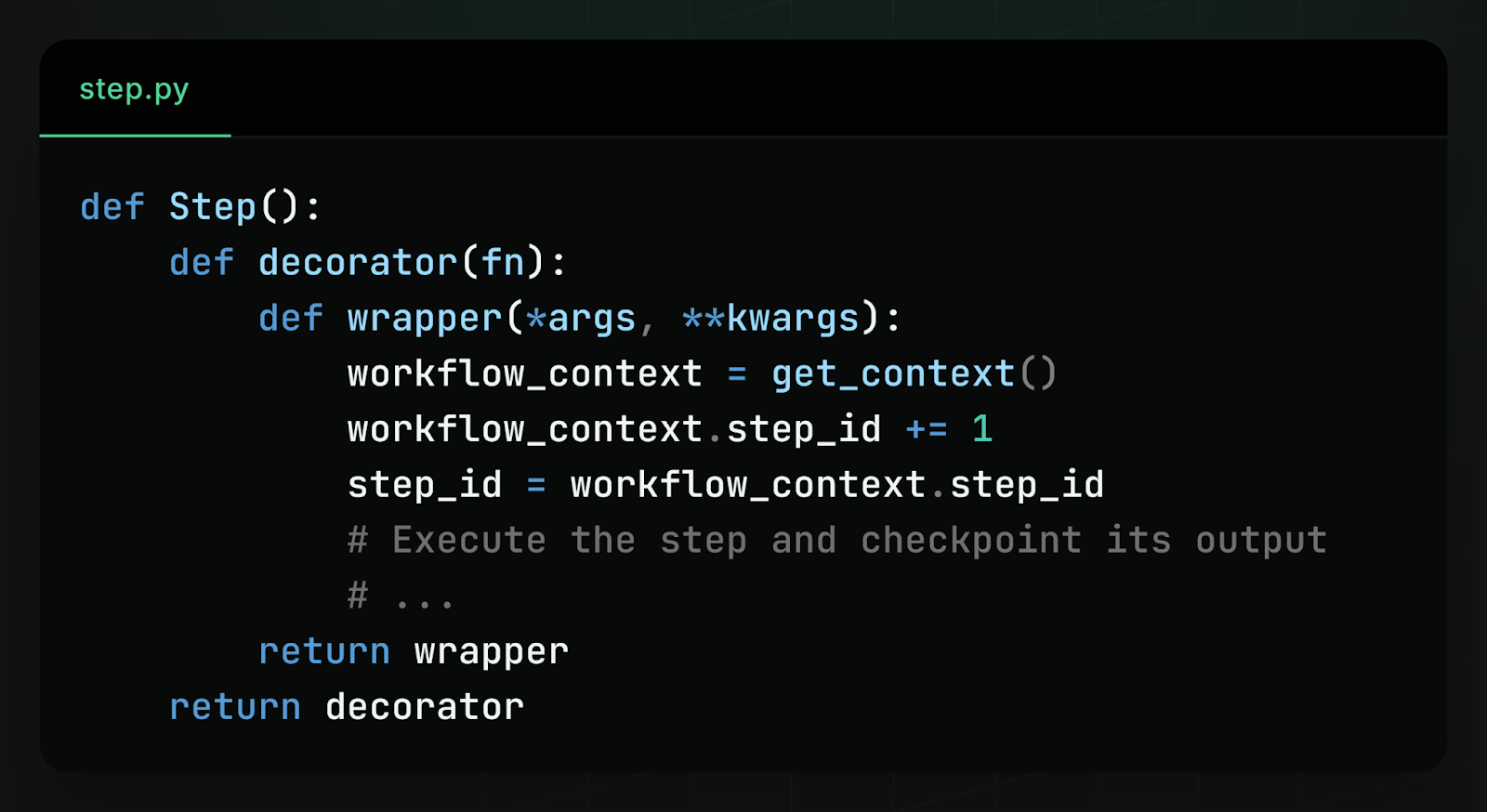
This makes it possible to deterministically order steps using code placed before the step’s first await. We can do this in the @Step() decorator, which wraps step execution. Before doing anything else, and in particular anything that might require an await, @Step() increments and assigns a step ID from workflow context. This way, step IDs are deterministically assigned in the exact order steps are passed into asyncio.gather. This guarantees that the step processing task one is step one, the step processing task two is step two, and so on.
To sum it up, when building Python libraries, it’s really important to understand the subtleties of asyncio and the event loop. While it might seem unintuitive at first, the single-threaded execution model is actually easier to reason about than parallel threads because tasks execute predictably and can only interleave when control is explicitly yielded via await. This makes it possible to write simple code that’s both concurrent and safe.
Learn More
If you like making systems reliable, we’d love to hear from you. At DBOS, our goal is to make durable workflows as easy to work with as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67