






A few weeks ago, we wrote that you should “just use Postgres” for durable workflows.
That post generated a lot of discussion, but also a misunderstanding. We didn't just mean you should use a workflow engine that stores state in Postgres. We meant your workflow system can, and often should, live inside the same Postgres database as your application.
At first glance, this doesn’t sound like a good idea. Shouldn’t those concerns be separated? Shouldn’t workflow state live in one database and application data in another?
Maybe not.
In distributed systems, co-location is a superpower. When workflow metadata and application data live in the same Postgres database, they can be updated in the same database transaction. That means partial failures are no longer possible, making it far easier to build workflows that correctly handle all edge cases.
In this post, we'll explain why that's possible, and how transactions can simplify tough problems like idempotency and atomicity.
Idempotency with Transactional Steps
One fundamental challenge in distributed systems is idempotency, especially for operations that modify database state.
Durable workflows achieve fault tolerance by checkpointing the result of each step after it completes. If a workflow is interrupted, it resumes from its last checkpointed step instead of starting from the beginning. However, a workflow may be interrupted after completing a step but before recording its checkpoint. When it recovers, it has no record that the step already ran and will execute it again.
As a result, durable workflows alone do not solve the idempotency problem. Workflow engines typically require steps to be idempotent so they can safely be retried without duplicate side effects. For example, consider a step that credits (add money to) a bank account. This is not an idempotent operation: if a step adds $100 to an account, fails, reruns, and adds $100 again, then a total of $200 is added to the account, which is not correct.
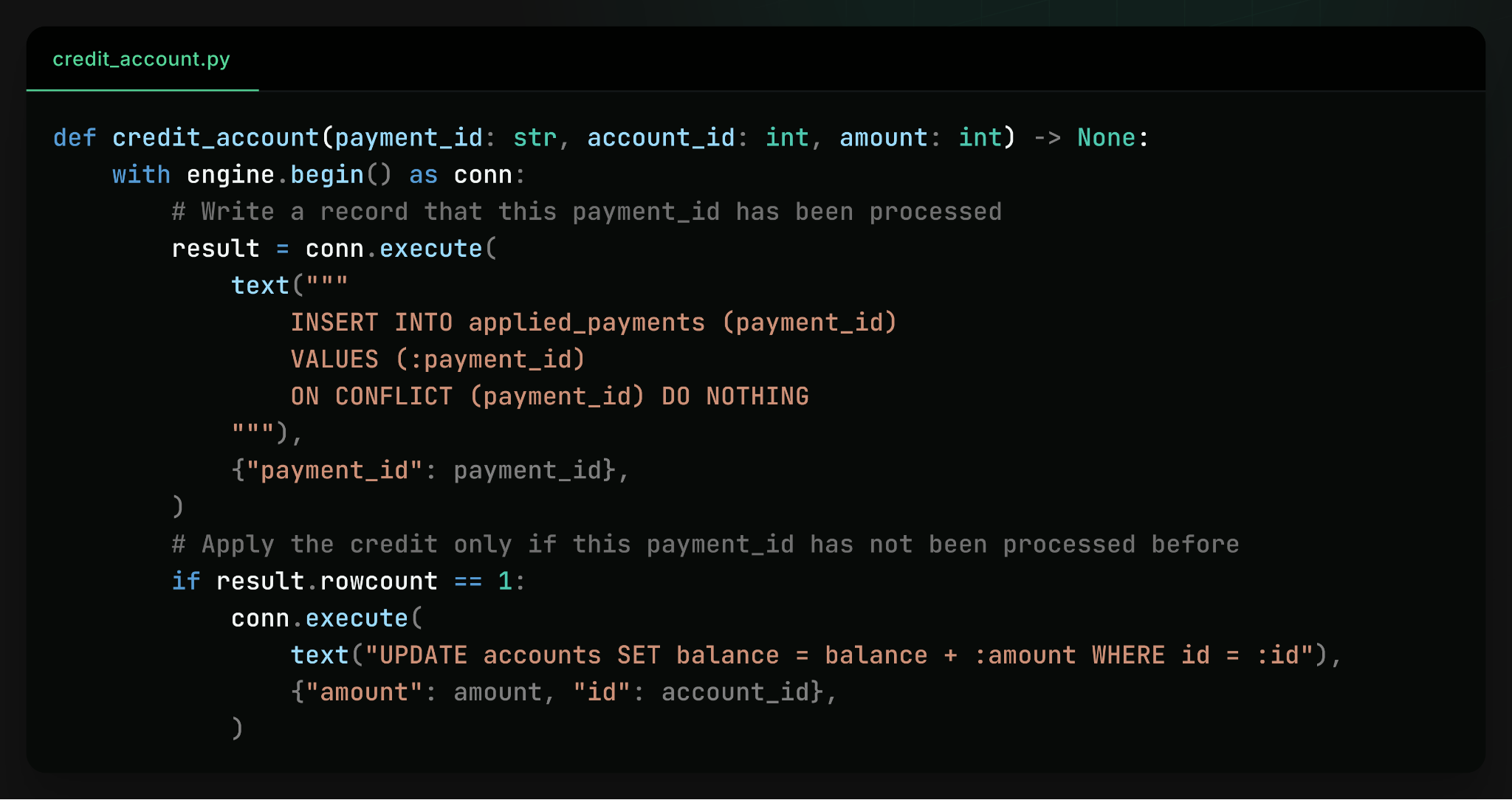
The most common solution is to add application-level bookkeeping to guard against this. For example, you can add an additional applied_payments table to keep track of which payments have been applied, update it transactionally, and check against it to make sure you never credit an account twice:
When workflow state and application data are co-located in the same Postgres database, we can eliminate much of this complexity. Instead of checkpointing a step after its database transaction commits, a co-located workflow engine can write the step checkpoint and perform the database update in the same transaction.
To do this, the workflow executes the step using a database transaction provided by the workflow engine. The step performs its database updates, the workflow engine records the checkpoint, and the whole transaction commits atomically:
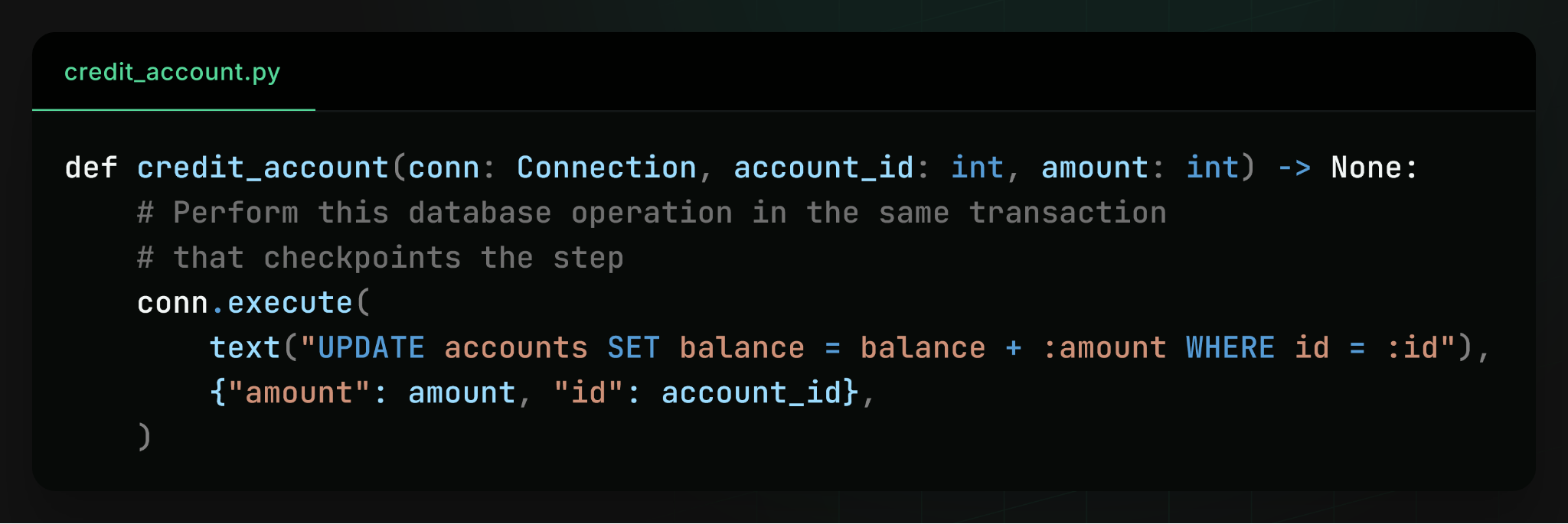
By making the database update and checkpoint write part of the same transaction, the workflow engine can provide exactly-once execution semantics for transactional steps:
- If the transaction commits, both the database update and the checkpoint are durably recorded, guaranteeing the step will never run again.
- If any failure occurs before commit, the entire transaction is rolled back, including both the database update and the checkpoint. When the workflow recovers, it safely re-executes the step from the beginning.
This eliminates the window in which a database update can succeed without a corresponding checkpoint. As a result, transactional steps no longer need application-level idempotency logic or bookkeeping tables. The database operation either happens exactly once and is checkpointed, or it does not happen at all.
Atomicity with a Transactional Workflow Outbox
Another classic challenge in distributed systems is reliably performing updates in multiple systems, for example, updating a database record and sending a notification to another system. This is trickier than it sounds because the operations need to be atomic: they either both happen or neither do, even if there are failures (such as process crashes or network glitches) while performing them.
For example, whenever a customer submits a new order, we may also want to start a workflow that sends the order to a warehouse for fulfillment. Without atomicity, the database and the downstream system may become inconsistent. The order might be submitted without a warehouse being notified, or a warehouse might be notified about an order that was never committed.
The most common solution to this problem is the transactional outbox. The idea is to maintain a new “outbox” table to the database. When we need to perform an atomic update, we run a single database transaction that both:
- Updates the database record
- Writes a message to the “outbox” table
A separate background process then polls the outbox table and delivers those messages there to the target system.
Here’s an example of what that might look like:
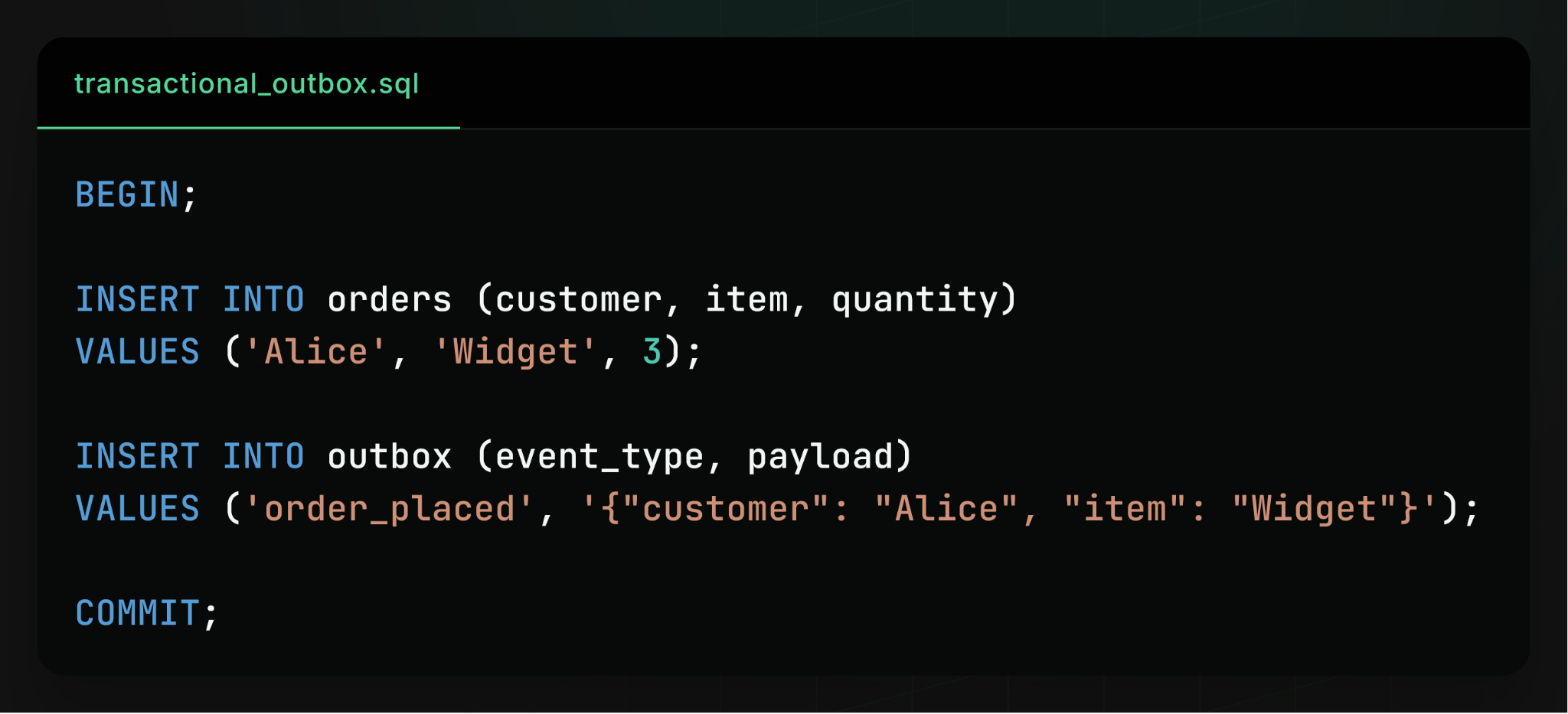
Performing the database record update and writing the message to the “outbox” table in one transaction guarantees atomicity: either both records are updated or neither are. Once a message is written to the outbox, it can be delivered asynchronously, even if failures occur after the transaction commits.
The transactional outbox is widely used, but it introduces additional operational complexity. You need infrastructure to poll the outbox, deliver messages, handle retries, and monitor failures. If the workflow engine is a separate system, it can drift out of sync with the database. In practice, resolving discrepancies requires additional infrastructure such as reconciliation jobs to detect database records that were updated without sending notifications to downstream systems.
By leveraging database-backed workflows and co-locating workflow state with application data, we can simplify this pattern. Instead of manually maintaining an outbox table and a separate polling process, we use a Postgres user-defined function (UDF) to enqueue a workflow in the same database transaction as the application update:
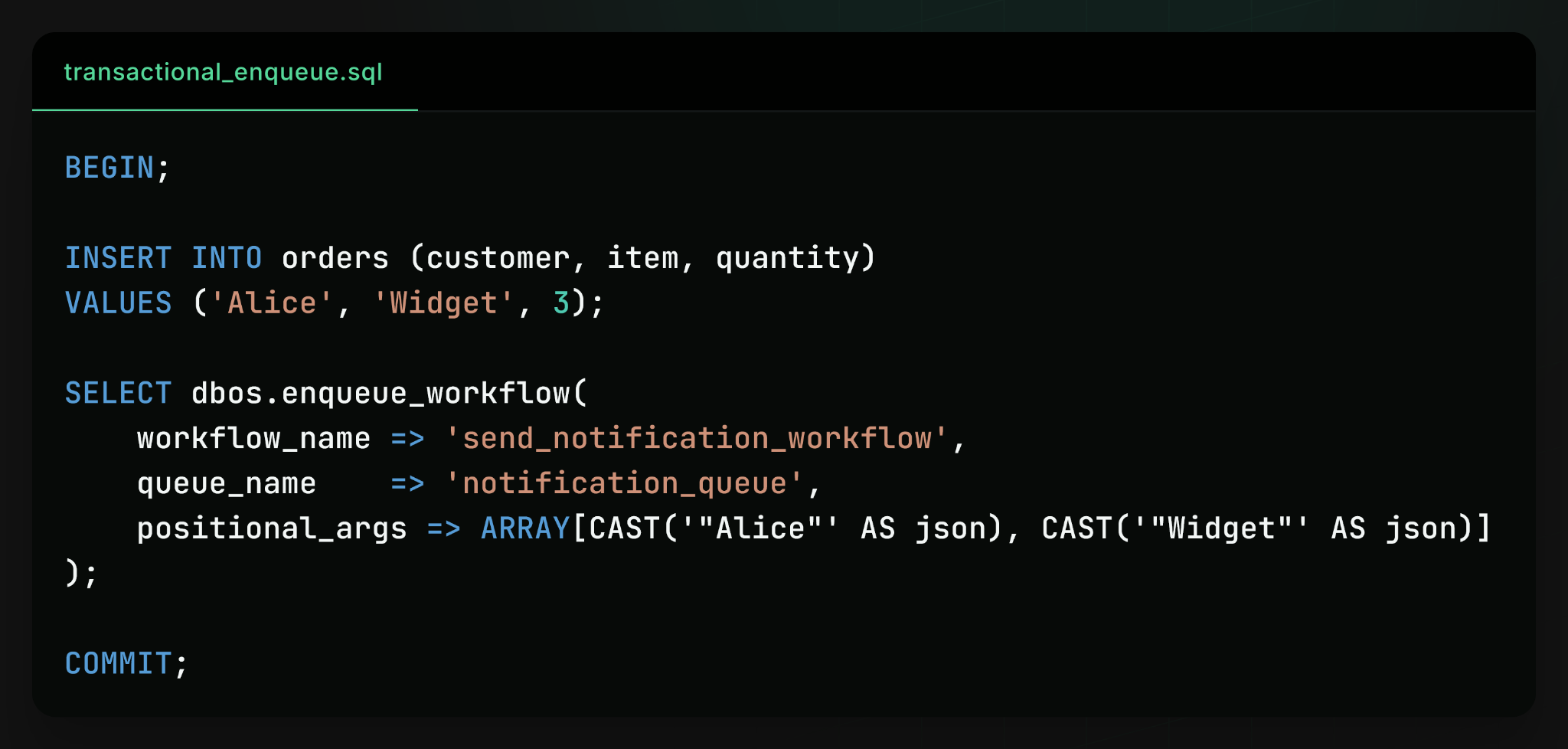
This works following the same principles as the transactional outbox. The workflow is represented by a database row containing its name, queue, and input. The enqueue_workflow UDF creates this row in the same transaction as the user database update, guaranteeing atomicity: either the update completes and the workflow is enqueued, or neither happens. Then, a worker dequeues and executes the workflow asynchronously, reliably performing the required operations.
Learn More
If you like building scalable, reliable systems, we’d love to hear from you. At DBOS, our goal is to make Postgres-backed durable execution as simple and performant as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67