






Every software developer knows that handling failures at scale is hard. If your business workflows are serving thousands or millions of customers across fleets of servers, and there's a major disruption, like a software bug or failure in a downstream service, then figuring out which customers were affected and how to recover is incredibly difficult, especially when those customers are understandably breathing down your neck asking when you'll un-break things.
To make it easier to recover from complex failures at scale, this post proposes a new primitive for software workflows: fork. Forking a workflow means restarting it from a specific step, on a specific code version. Essentially, this lets you "rewind time" and restart your workflow from before a failure happened, after you fix the cause of the failure. We'll show how fork simplifies operating complex workflows in production and sketch one practical implementation of it.
Handling Workflow Failures Is Hard
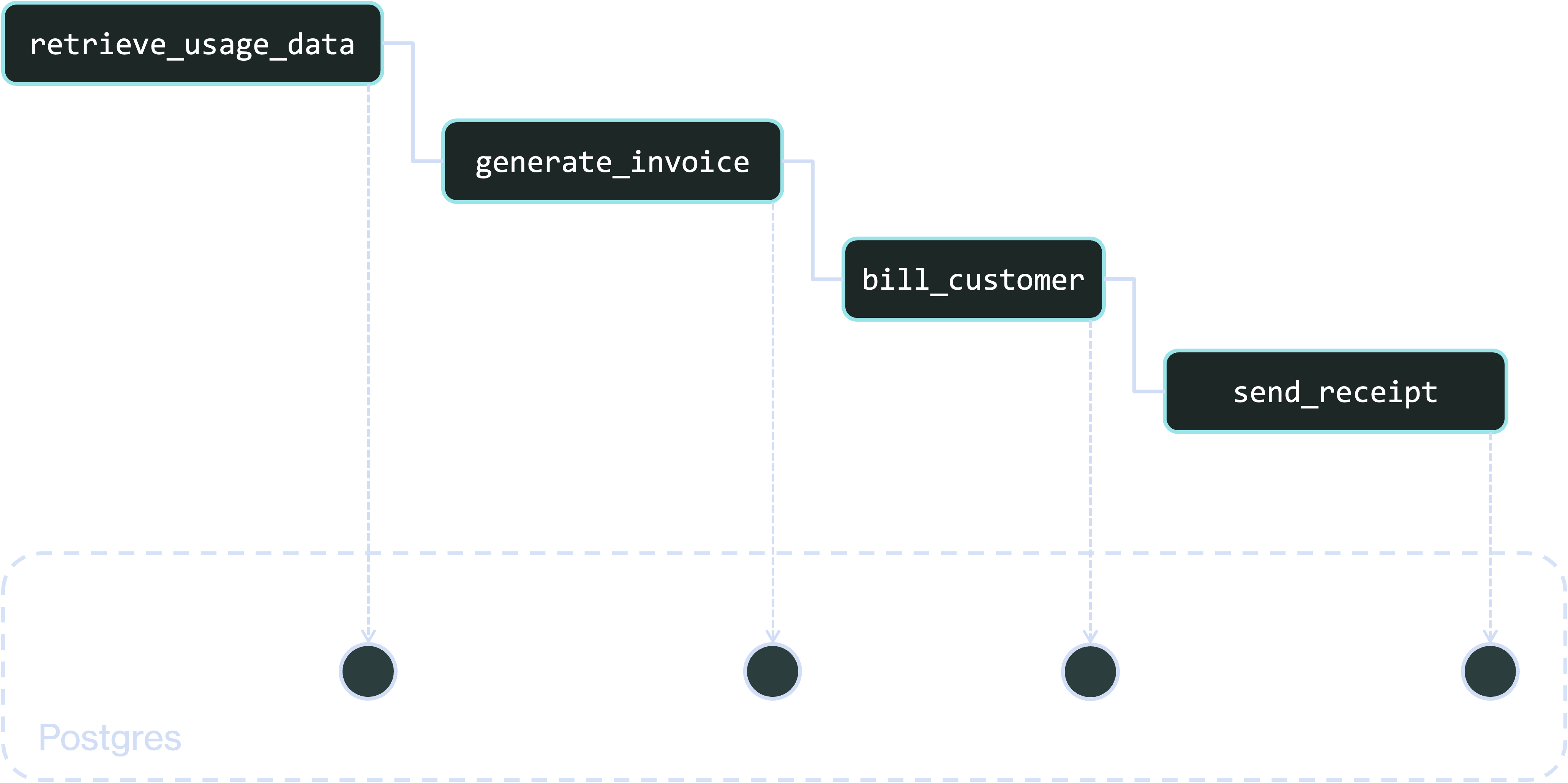
Say you’re building a system that bills customers monthly based on their usage. Every month, for each customer, it looks up their usage, generates an invoice, bills them with the invoice, then sends a receipt. Your system probably contains a workflow that, at a high level, looks like this:
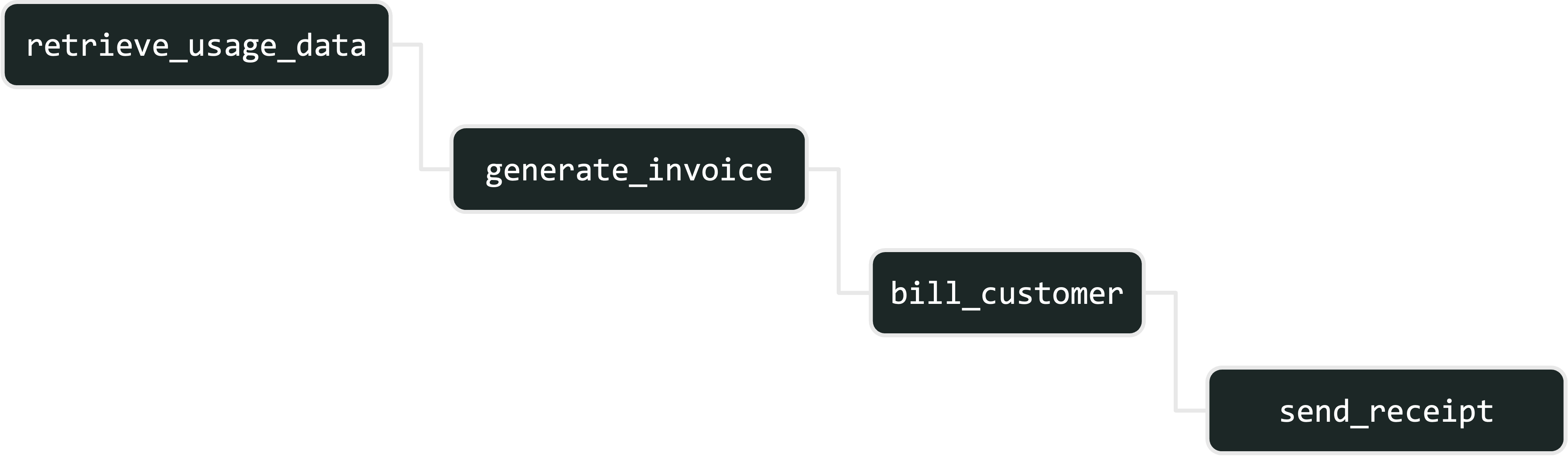
The biggest challenge in operating workflows like this is handling failures. For example:
- Your payment service may experience an outage. For a period of time, all attempts to bill customers fail. After the outage is resolved, you have to identify which customers weren’t billed and bill them.
- Your invoice generation code may have a localization bug. For customers from a particular country, it generates invalid invoices which can’t be billed. After this issue is identified, you have to identify which customers were affected and bill them with correct invoices.
Handling failures in workflows is especially difficult because workflows often have complex dependencies between steps. For example, the billing workflow bills customers using a specific invoice generated over a specific billing period. When recovering from a billing outage, you ideally wouldn’t rerun the billing workflow from scratch as that could use the wrong billing period. Instead, you want to reuse the invoices your workflow has already generated. Moreover, workflows often run at scale, so issues like an outage or a bug affect not just one or two customers, but thousands–and all of them would like this resolved fast as they have their own financials to manage. Therefore, failure recovery needs to be context-aware, timely, and programmatic, and writing code to do this robustly is hard.
Workflow Forking To The Rescue!
Now, let’s see how workflow fork can help recover from these failures. To recap, forking a workflow means restarting it from a specific step and code version, while reusing the previously computed results of all earlier steps. This allows developers to recover from failures or apply fixes without repeating work that was already completed successfully.
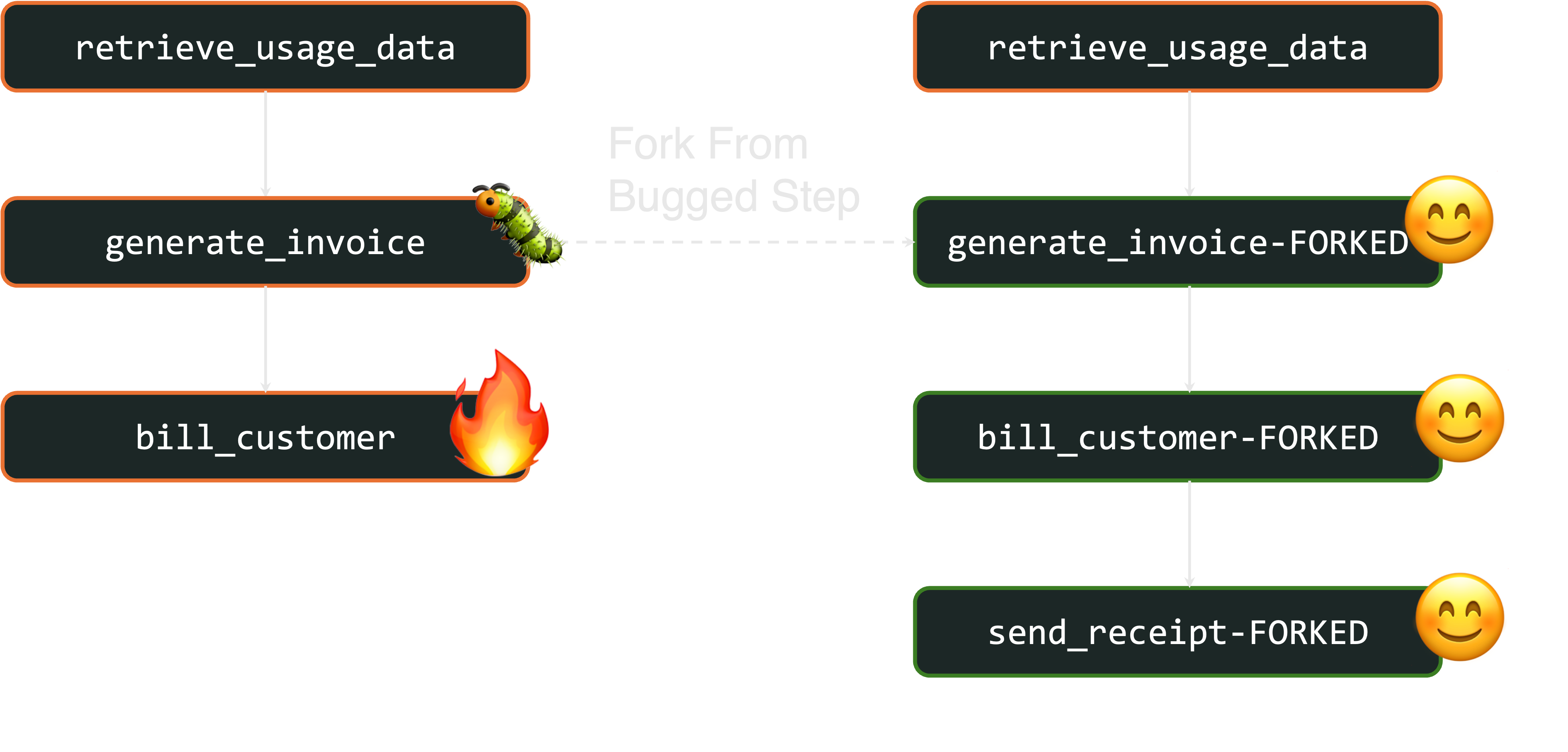
Let’s examine the first example failure: an outage in the payment platform that causes billing to fail. If this occurs, we’ll have thousands of workflows that look like this, where usage data was retrieved successfully and an invoice was generated, but billing failed because of the outage:
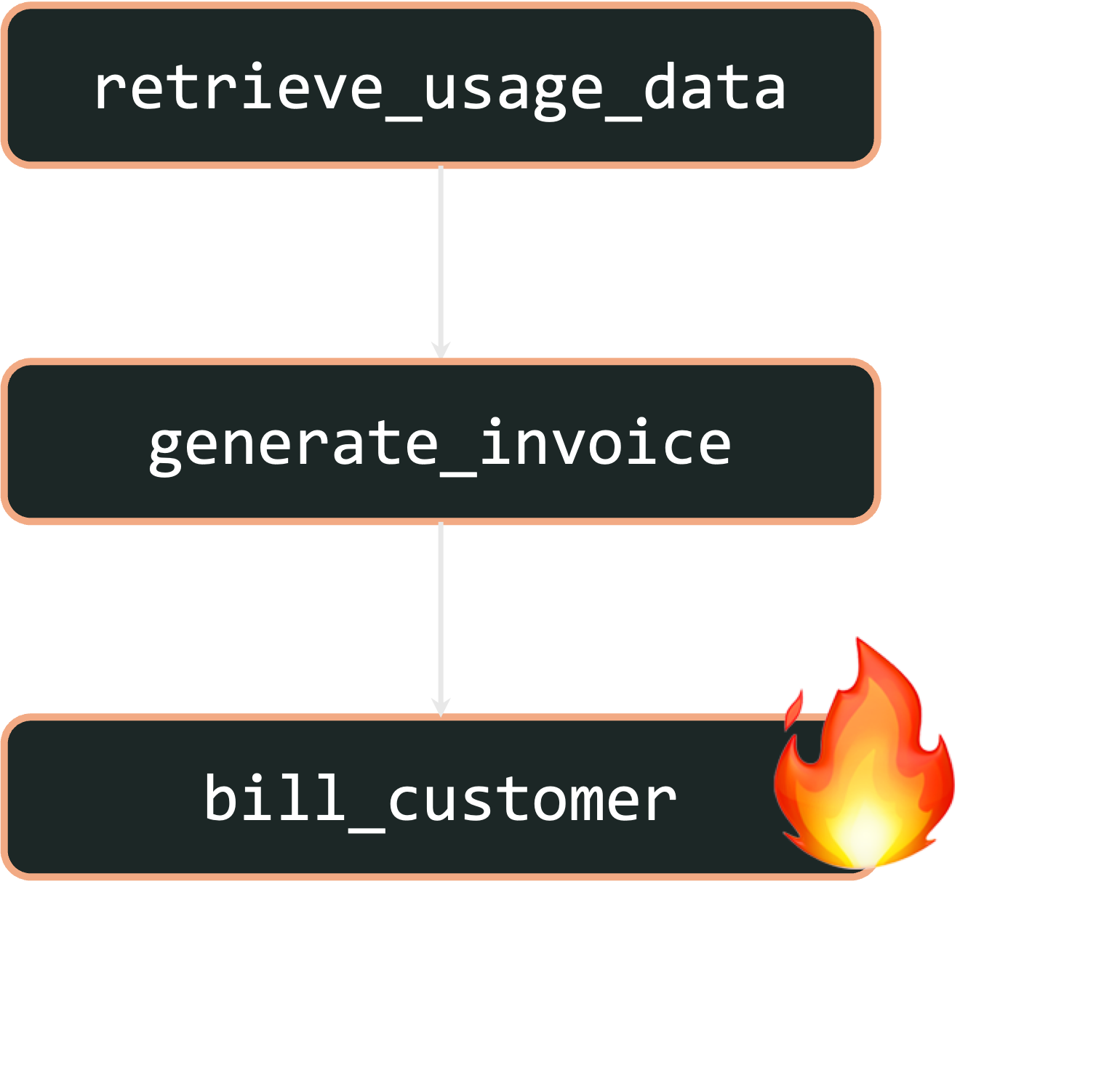
With fork, after the outage is resolved, you can restart each failed workflow from the billing step. This automatically reuses the previously-generated invoice to successfully bill each customer:
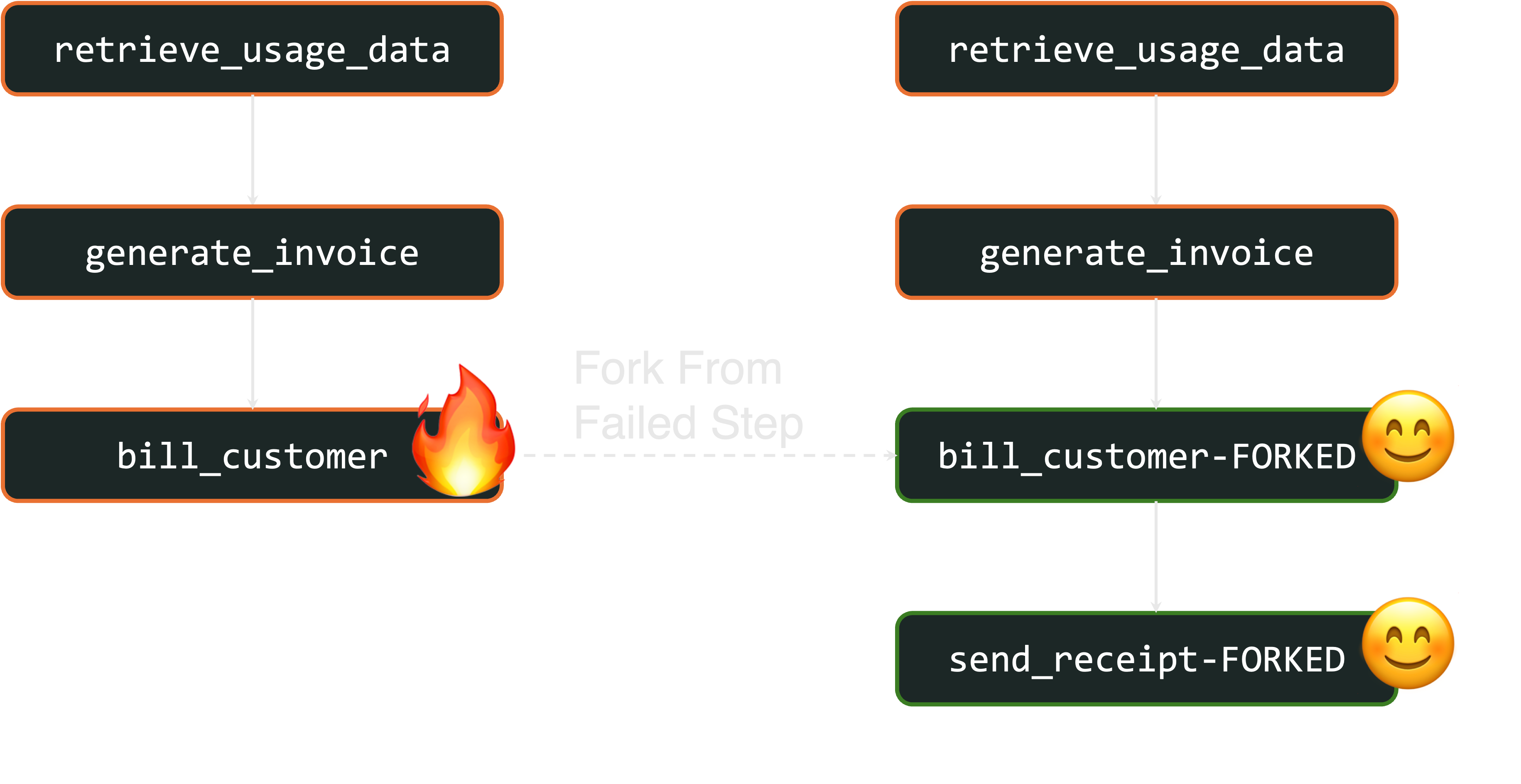
Alternatively, let’s look at the second failure: a localization bug in generating invoices that causes billing to fail. If this occurs, customers from the affected regions will have workflows that look like this:
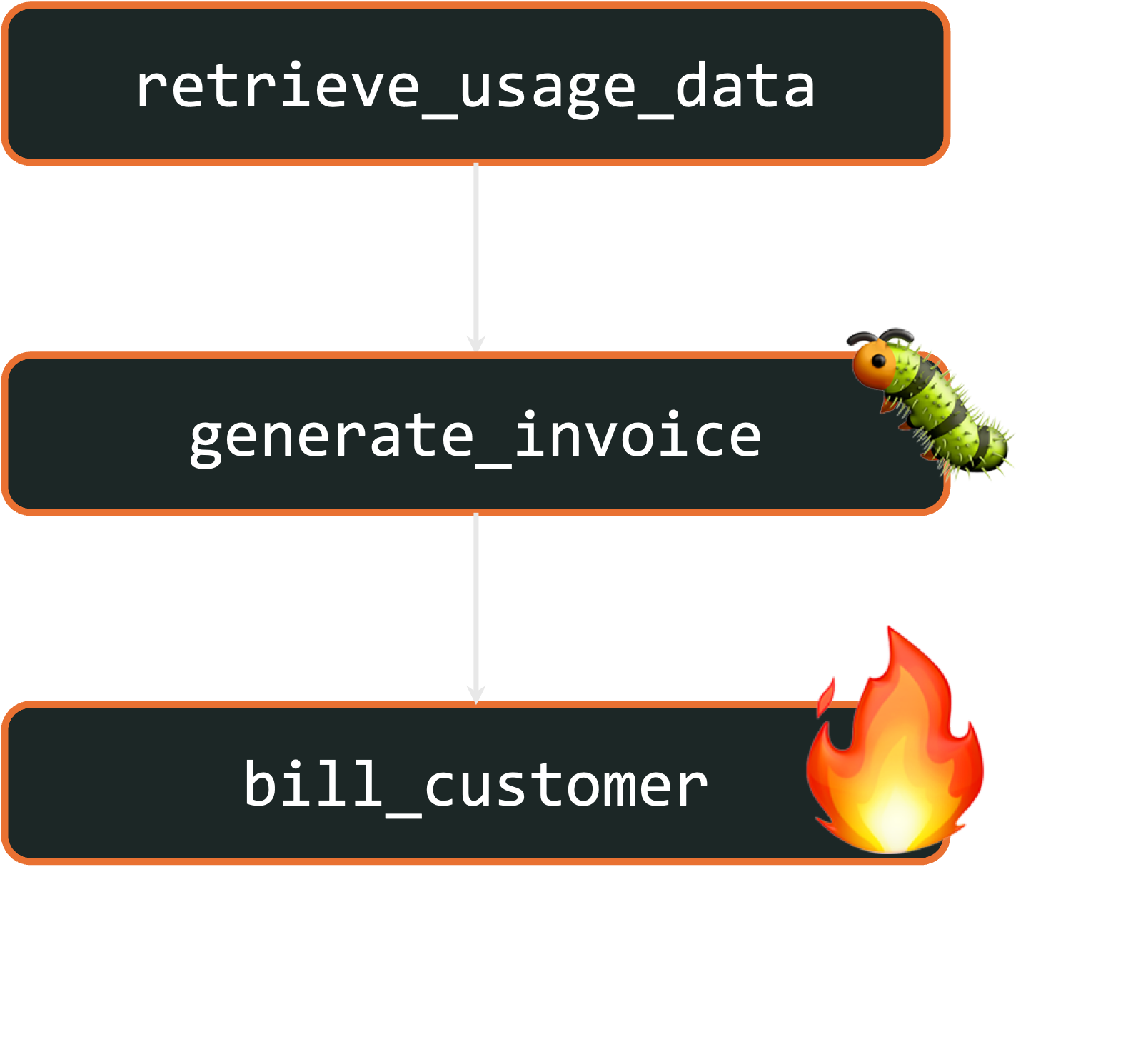
With fork, after the bug is fixed, you can restart each workflow from the invoice generation step on the fixed code. This automatically reuses the previously-collected usage data for the appropriate billing period to successfully invoice and bill affected customers:
How Workflow Forking Works
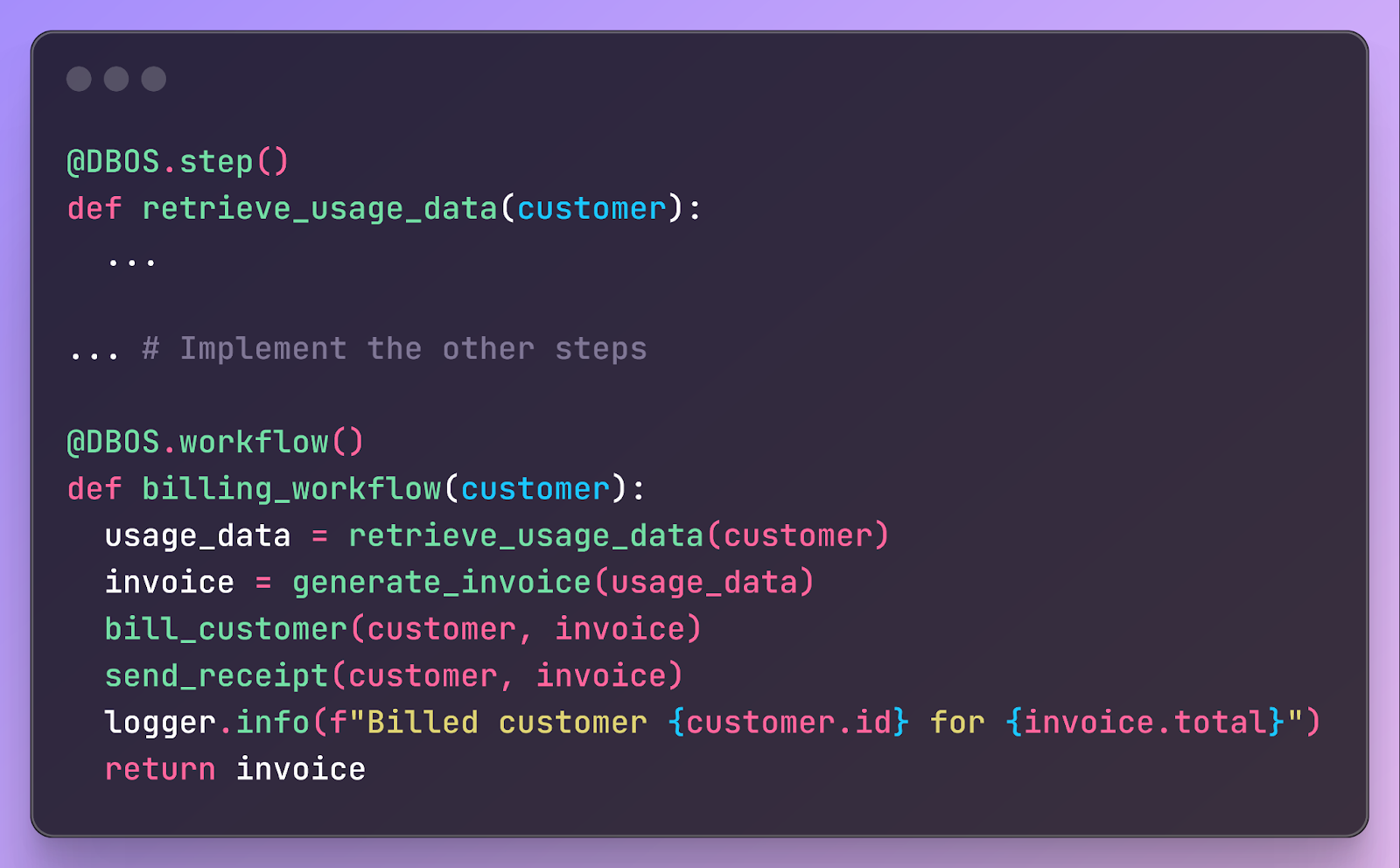
Part of the power of fork is that you can implement it in almost any workflow engine as long as it stores enough information about completed steps. To make this more concrete, we’ll sketch how fork works inside the workflow engine we’re building at DBOS. At a very high level, in DBOS you declare workflows and steps by annotating your code like this:
And those annotations checkpoint workflows and steps into a database like this:
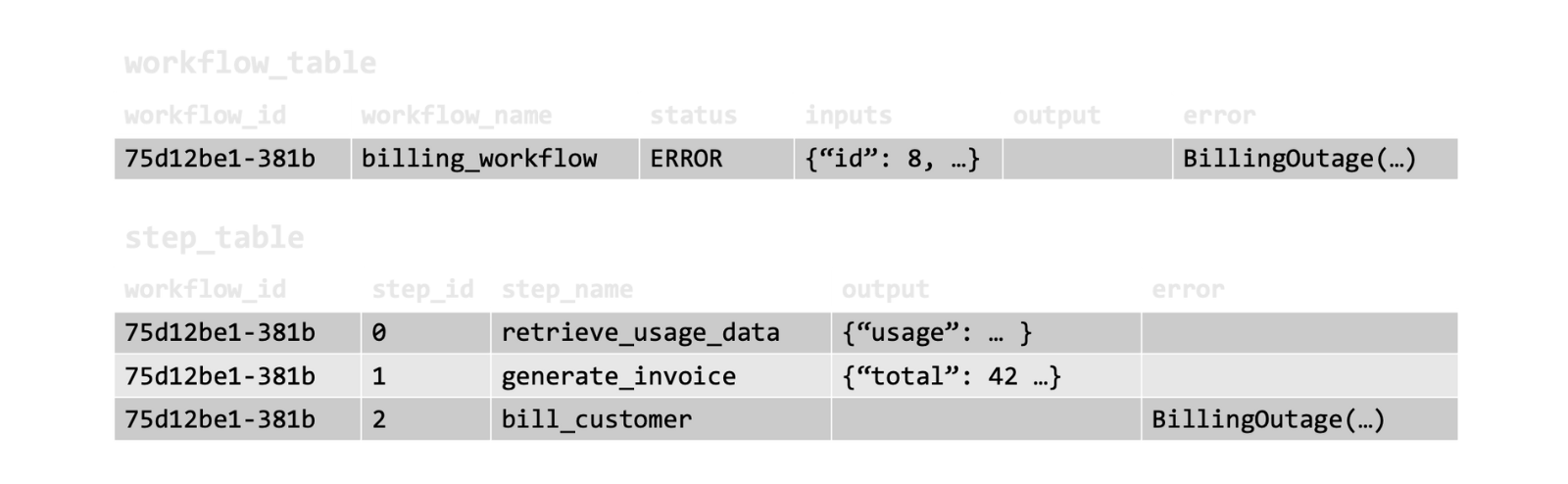
Here’s what the checkpoints look like for a workflow that failed due to a billing outage. There’s an entry for the workflow in the workflows table and for each step in the steps table. The entry for each step contains the outcome of the step: the retrieved usage data, the generated invoice, and the billing outage error.
Given these checkpoints, you can fork the workflow by copying its inputs and checkpoints up to the failed billing step into a new PENDING workflow:

Using the information stored in these rows, the forked workflow can resume from the billing step, reusing the checkpointed usage data and invoice to successfully bill the customer.
If you need to recover billing for thousands of affected customers, you can write a short script that queries the workflow and step tables to find affected workflows and fork them:
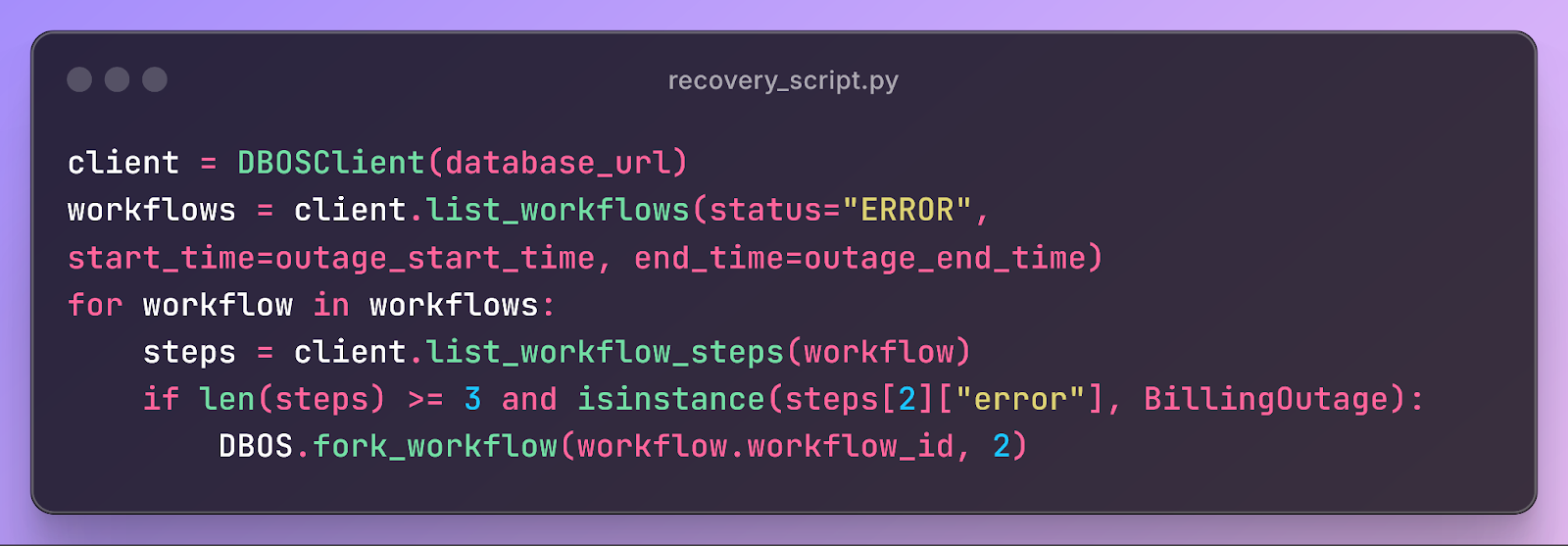
This pattern is extremely powerful and general. If you can represent your business processes as workflows and fork them, you can more easily recover from complex failures affecting thousands or millions of users, including outages in downstream services, bugs in application code, and failures in dependencies.
Try It Out
At DBOS, we’re trying to make workflows as lightweight and easy to work with as possible. Check us out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Docs for fork: https://docs.dbos.dev/python/tutorials/workflow-management