





A big problem developers face when building AI agents is debugging the weird or unexpected things they do. For example, an agent might:
- Return a malformed structured output, causing a tool call to fail.
- Invoke the wrong tool or the right tool with the wrong inputs, causing the tool to fail.
- Generate an undesirable or inappropriate text output, with potentially serious consequences.
While any program might sometimes do something unexpected, the problem is especially bad for LLM-driven AI agents because they’re fundamentally nondeterministic. The steps an agent takes are determined by prompting an LLM, and there’s no easy way to know in advance how an LLM will respond to a prompt, context, or input.
This nondeterminism makes bad behavior hard to reproduce or fix, especially for complex or long-running agents. If an agent does something wrong after an hour of iteration, the accumulation of nondeterminism makes the misbehavior nearly impossible to reproduce if you’re starting from the beginning.
When viewed through this lens, misbehaving agents are primarily an observability and reproducibility problem. If the correctness of an agent can only be determined empirically, then the only way to make agents reliable is to be able to reliably reproduce their failures. Then, we can analyze root causes, fix them, and build new test cases and evals.
One tool that can help with this problem is durable workflows. These work by checkpointing every step a program takes to a database, creating a durable record of its progress. When applied to an agent, this means checkpointing every LLM or tool call made by the agent, thus durably recording its trajectory.
Originally, durable workflows were developed to provide resilience to process crashes and hardware failures: if a process stops, the workflow can recover from its checkpoints to restore its exact state and continue from where it left off. What's interesting is how this recovery makes it easier to debug AI agents. While an agent makes nondeterministic choices at each step of its execution, every step invocation in the agent's workflow is determined by the outputs of the previous steps. By checkpointing step outcomes, durable workflows can “remember” the choices an agent made. This creates a replayable trace of an otherwise unpredictable system, helping reproduce complex bugs.
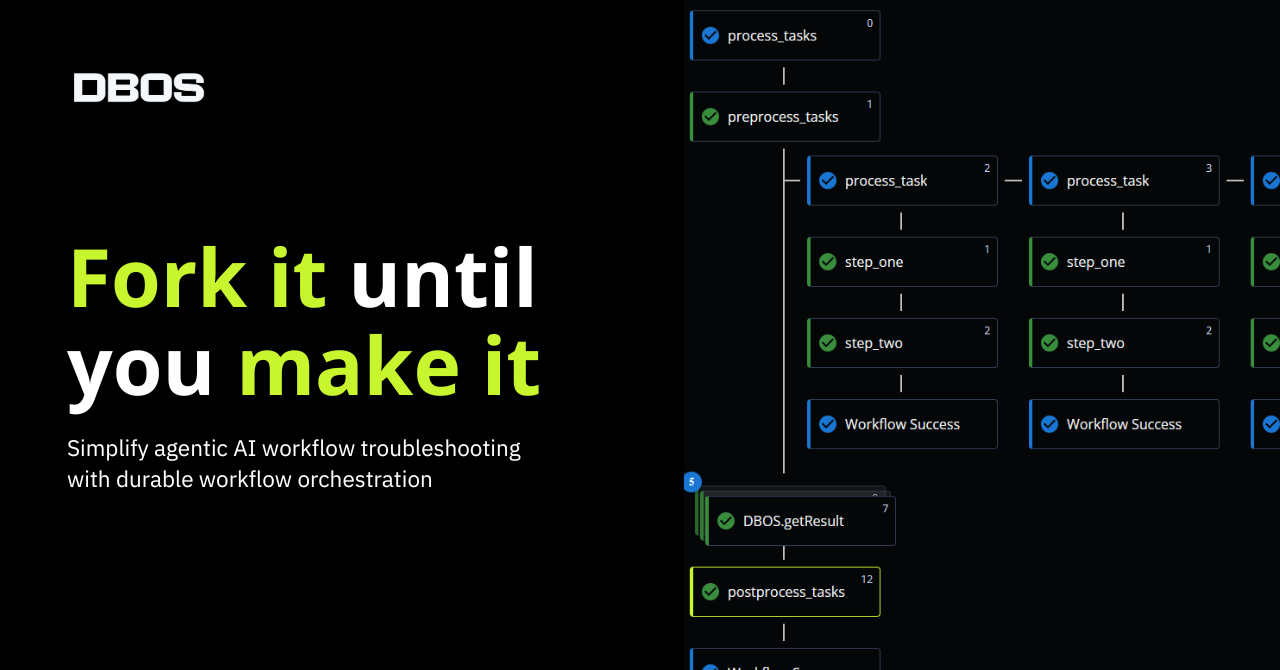
Fork it Until You Make It
The first benefit of durable workflows is observability. Because they checkpoint every LLM and tool call, they naturally create a record of an agent’s progress up to an instance of bad behavior. You can query that record to visualize the agent’s activity and see exactly what the failure was and what state (prompt, context, input) preceded it.
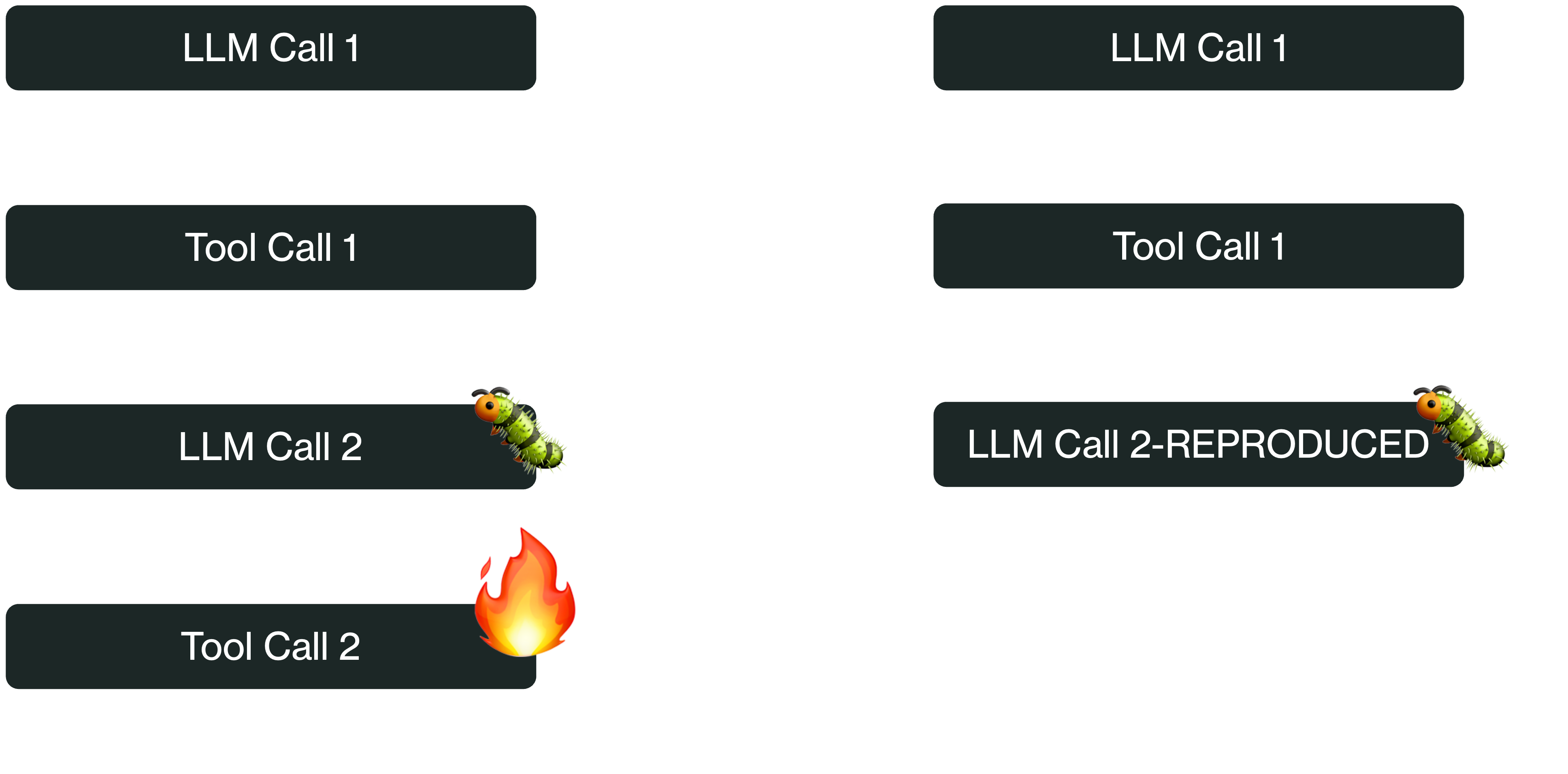
However, observability only goes so far. To really fix an issue, you don’t want to just stare at logs of its last occurrence–you need to reproduce it. This is what durable workflows do best. Durable workflows were originally invented to recover programs from process crashes by restoring their exact state from checkpoints. By extension, they can restore a program (like your agent) to any previous state, such as the state it was in immediately prior to the bad behavior.
The most useful form of this operation is forking a workflow. The idea is to create a “forked” copy of a workflow containing all its checkpoints up to a specific step.Then, you can start the workflow and it will begin execution from the target step, letting you reproduce its misbehavior. Think of this like a “git branch” for workflow execution, where you create a separate “branch” of your workflow that diverges from a specific step:
One non-obvious benefit of this reproducibility is that you can rapidly iterate on and test fixes. Once you’ve identified the source of the issue, apply a fix to the misbehaving step, fork and restart the workflow from that step, check if the issue was fixed, and repeat until successful. Being able to isolate and iterate on the problematic steps is especially useful for complex agents where testing from scratch would take a long time and burn too many tokens.
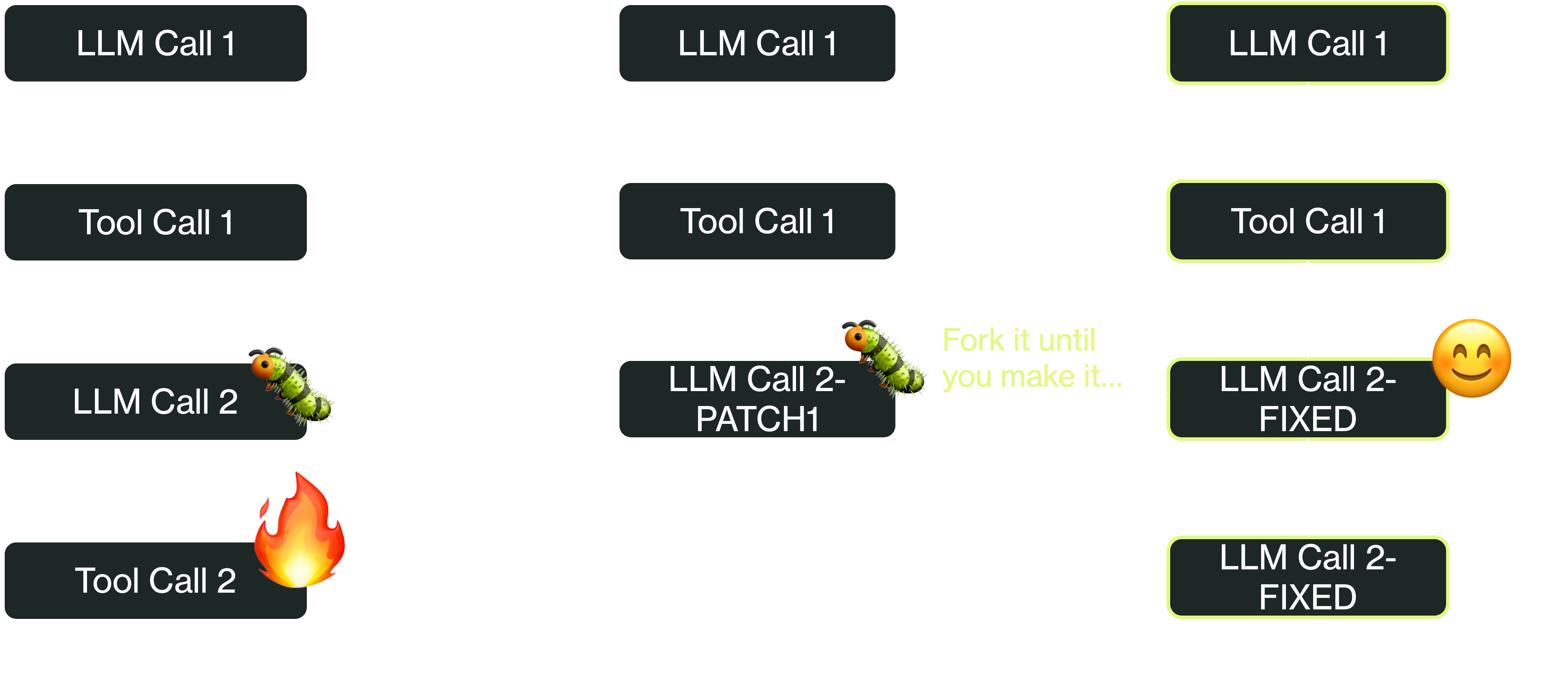
Essentially, the idea is to use workflows to impose determinism on fundamentally nondeterministic agents. Checkpointing every step an agent takes in a database makes it possible to reconstruct the agent’s state at any point in time, which makes it much easier (and costs far fewer tokens) to figure out why the agent is doing something weird and fix it.
Learn More about Agentic AI Workflow Orchestration
Here’s a video showing a workflow fork in action:
If you like making systems reliable, we'd love to hear from you. At DBOS, our goal is to make durable workflows as lightweight and easy to work with as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67