
.png)







When I was responsible for the infrastructure at Reddit, the most important thing I maintained was Postgres, but a close second was RabbitMQ, our message broker. It was essential to the operation of reddit — everything went into a distributed queue before it went to a database. For example, if you upvoted a post, that was written to the queue and the cache, and then returned success to the user. Then a queue runner would take that item, and attempt to write it to the database as well as create a new work item to recalculate all the listings that upvote affected.
We used this task queue architecture because it was simple and scalable with powerful features:
- Horizontal scalability. Task queues let us run many tasks in parallel, utilizing the resources of many servers. They were also fairly simple to scale–just add more workers.
- Flow control. With task queues, we could customize the rate at which workers consume tasks from different queues. For example, for resource-intensive tasks, we could limit the number of those tasks that can run concurrently on a single worker. If a task accesses a rate-limited API, we could limit how many tasks are executed per second to avoid overwhelming the API.
- Scheduling. Task queues let us define when or how often a task runs. For example, we could run tasks on a cron schedule, or schedule tasks to execute some time in the future.
This system scaled well, but it could break in all sorts of tricky ways. If the databases for votes were down, the item would have to go back onto the queue. If the listings cache was down, the listings couldn’t get recalculated. If the queue processor crashed after it had taken the item but before it acted on it, the data was just lost. And if the queue itself went down, as it was prone to do, we could just lose votes, or comments, or submissions (did you ever think “I know I voted on that but it’s gone!” when using reddit? That’s why).
What we really needed to make distributed task queueing robust are durable queues that checkpoint the status of our queued tasks to a durable store like Postgres. With a durable queue, we could have resumed failed jobs from their last completed step and we wouldn’t have lost data when there were program crashes.
Durable queues were rare when I was at Reddit, but they’re more and more popular now. Essentially, they work by combining task queues with durable workflows, helping you reliably orchestrate workflows of many parallel tasks. Architecturally, durable queues closely resemble conventional queues, but use a persistent store (typically a relational database) as both message broker and backend:
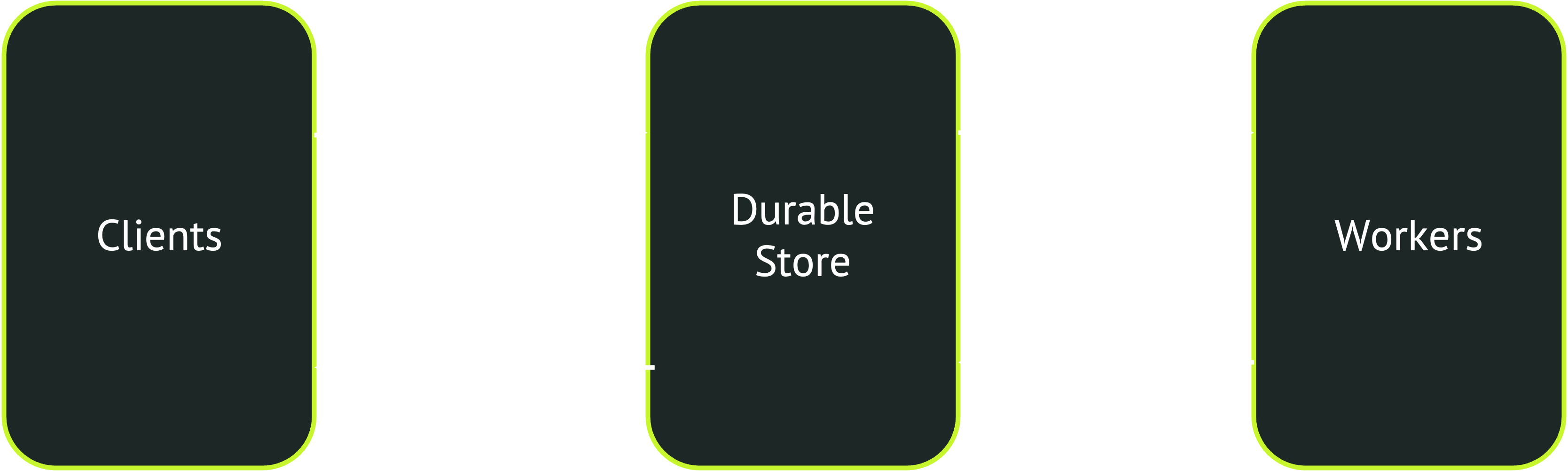
The core abstraction in durable queues is a workflow of many tasks. For example, you can submit a document processing task that splits a document into pages, processes each page in parallel in separate tasks, then postprocesses and returns the results:
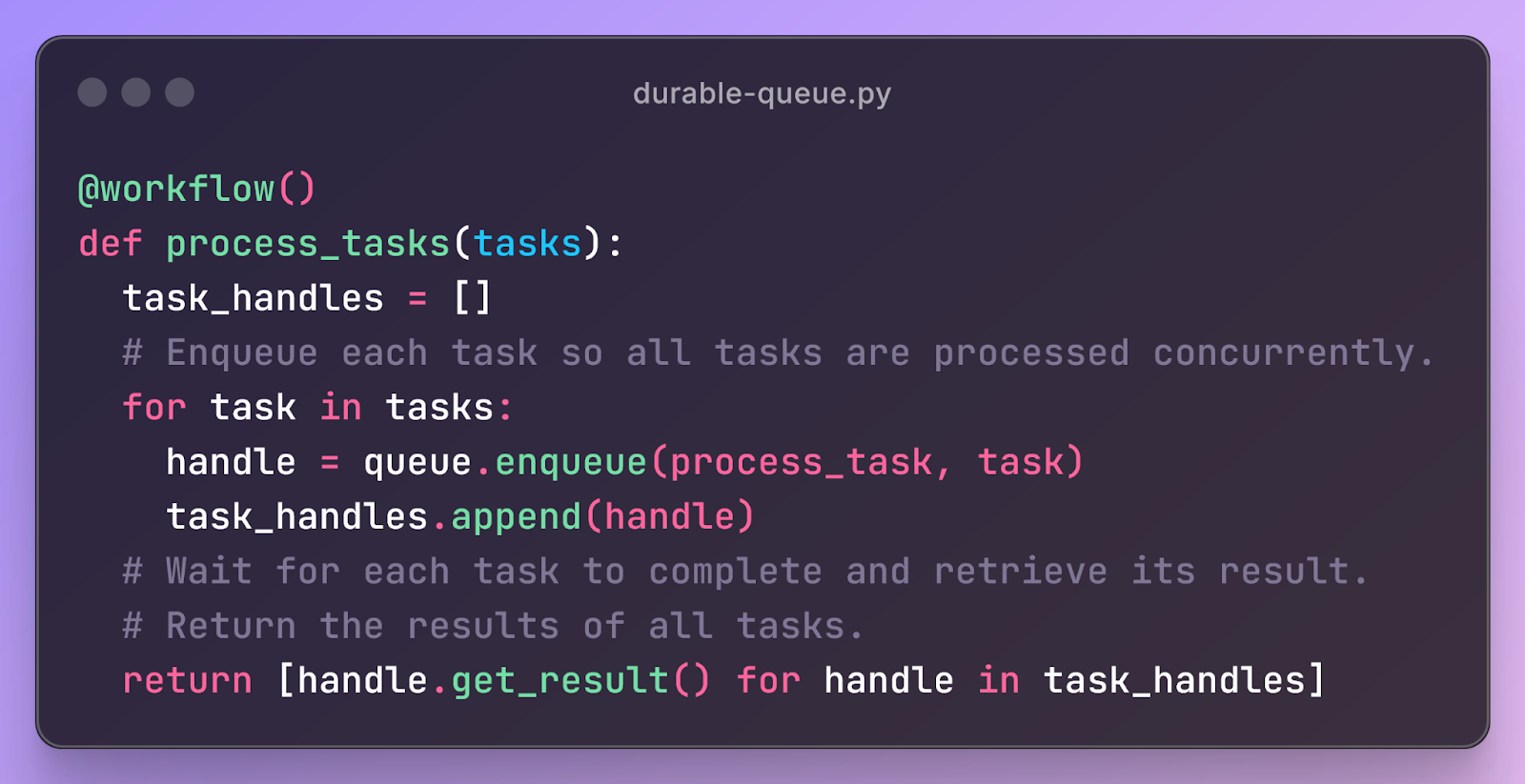
Durable queues work by checkpointing workflows in their persistent store. When a client submits a task, the task and its inputs are recorded. Then, whenever that task invokes another task, this subtask and its inputs is recorded as a child of its caller. Thus, the queue system has a complete persistent record of all tasks and their relationships.
These workflows are most relevant when recovering from failures. If a non-durable worker is interrupted while executing a task, the queue restarts it from the beginning at best, or loses the task at worst. This isn’t ideal for long-running workflows or tasks with critical data. Instead, when a durable queue system recovers a workflow, it looks up its checkpoints to recover from the last completed step, avoiding resubmission of any completed work.
Durable Queues and Observability
Another advantage of durable queues is built-in observability. Because they persist detailed records of every workflow and task that was ever submitted, durable queues make it easy to monitor what queues and workflows are doing at any given time. For example, looking up the current contents of a queue (or any past content) is just a SQL query. Similarly, looking up the current status of a workflow is another SQL query.
Durable Queueing Tradeoffs
So, when should you use durable queues? As always, the answer comes down to tradeoffs. For durable queues, the main tradeoff is around message broker performance. Most distributed task queues use an in-memory key-value store like Redis for brokering messages and storing task outputs. However, durable queues need to use a durable store, often a relational database like Postgres, as both message broker and backend. The latter provides stronger guarantees, but the former higher throughput. Thus, you should prefer durable queues when handling a lower volume of larger business-critical tasks and distributed task queues when handling a very large volume of smaller tasks.
Additional Reading on Durable Workflow Queueing
- Dosu - migrating queuing from Celery to DBOS
- Bristol Myers Squibb - durable, observable horizontal scaling of genomic data pipelines with DBOS
- cStructure - migrating queuing from Celery to DBOS
- DOCS: DBOS durable queuing