






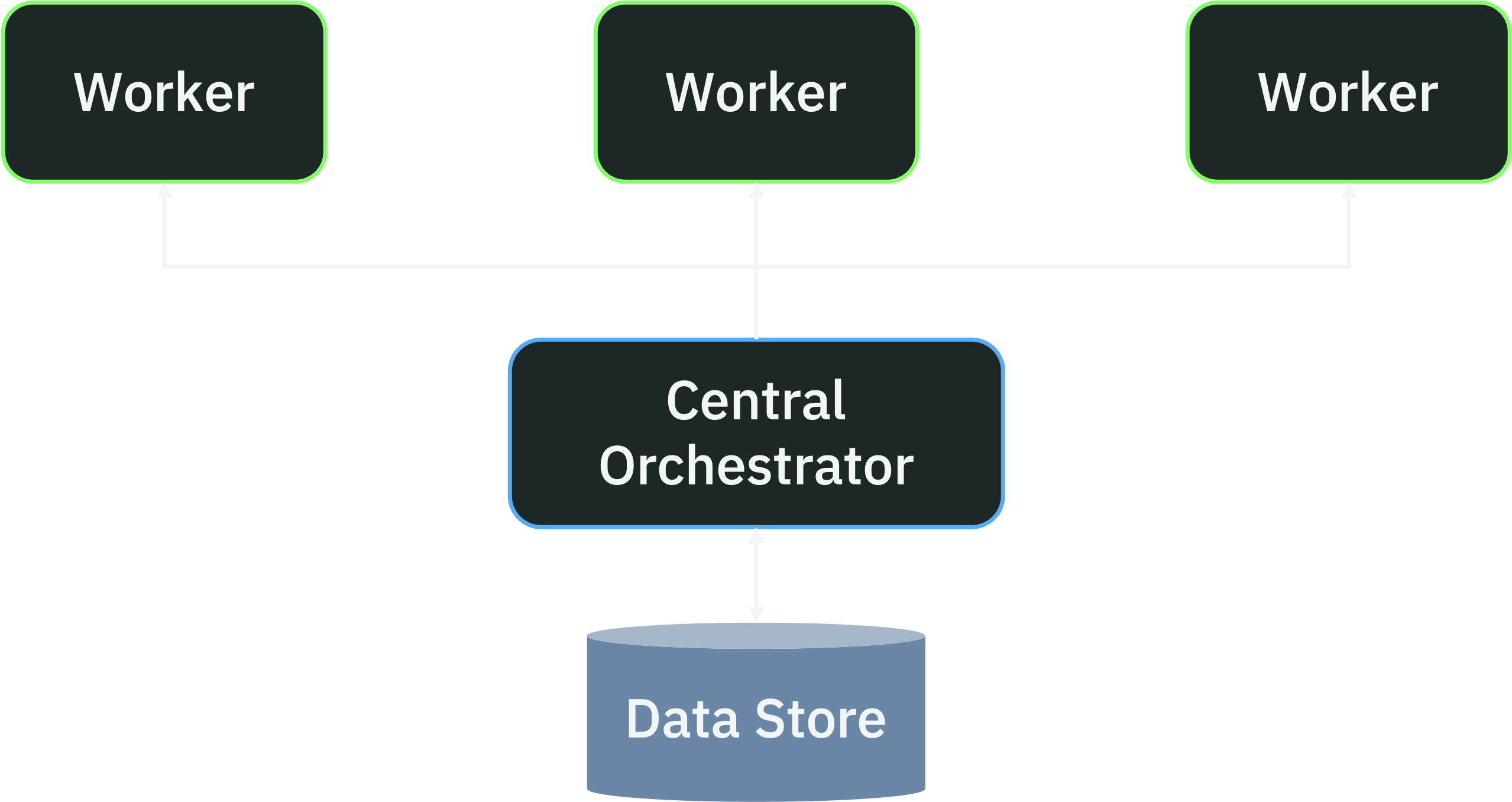
There are two ways you can implement durable workflows: centralized and decentralized. Most workflow systems (like Temporal or Airflow) are centralized: there’s a central server that orchestrates workflow execution, dispatching tasks to workers and checkpointing workflow state to a data store. Control flow and state management are handled by this central orchestrator.
By contrast, in a decentralized workflow system, there is no central orchestrator. Each server executes workflows as normal functions, using a library to checkpoint workflow state to a data store after each step.
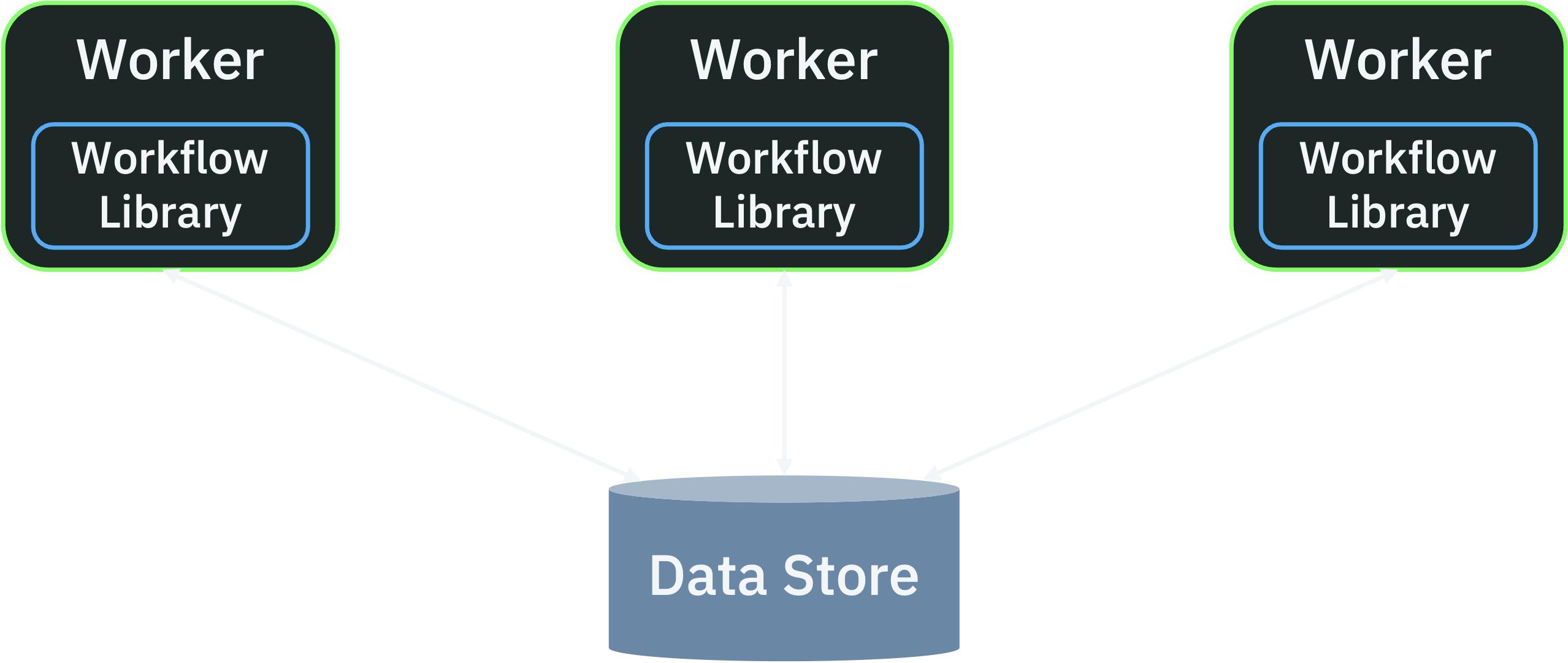
To be clear, the data store is still a central store of state (if it weren't, the workflows wouldn’t be durable!). But there’s no central orchestrator to tell workers what to do. Instead, independent application servers have to cooperate with each other to schedule and execute workflows, coordinating only through the shared data store.
We’re interested in decentralized workflows because they’re inherently simpler to adopt and operate: you don’t need to manage a workflow server or rearchitect your application to run workflows on dedicated workers. Moreover, decentralized workflows don’t introduce a new single point of failure (as you can use the same database you already use for data). However, like any decentralized system, they’re challenging to implement correctly or make performant at scale.
In this blog post, we’ll dive deep into the technical challenges of building decentralized workflows. These challenges arise because decentralized servers need to cooperate to process workflows, but can’t directly communicate with each other. We’ll show how to solve these challenges by leveraging database integrity properties and carefully applied randomness. In particular, we’ll look at:
- How to safely resolve conflicts when multiple servers try to process the same workflow.
- How to make decentralized cron scheduling efficient at scale.
- How to implement efficient decentralized queues.
Conflicting Workflow Executions
One tricky situation that can arise in a decentralized workflow system is duplicate workflow executions. For a variety of reasons (duplicate requests arriving at different servers, premature workflow recovery), two servers may try to execute the same workflow simultaneously.
Duplicate workflow execution is problematic because it risks violating workflow guarantees. A duplicated workflow may obtain different results from steps than the original, potentially creating multiple parallel workflow histories.
We’ll resolve workflow duplication by leveraging database integrity constraints. To make this clearer, let’s look at how workflows execute steps. Before executing a step, a workflow checks if a checkpoint already exists for the step in the database, meaning the step has already been executed. If no checkpoint exists, the workflow executes the step, then checkpoints the step’s outcome to the database. Here’s what this looks like in pseudocode:
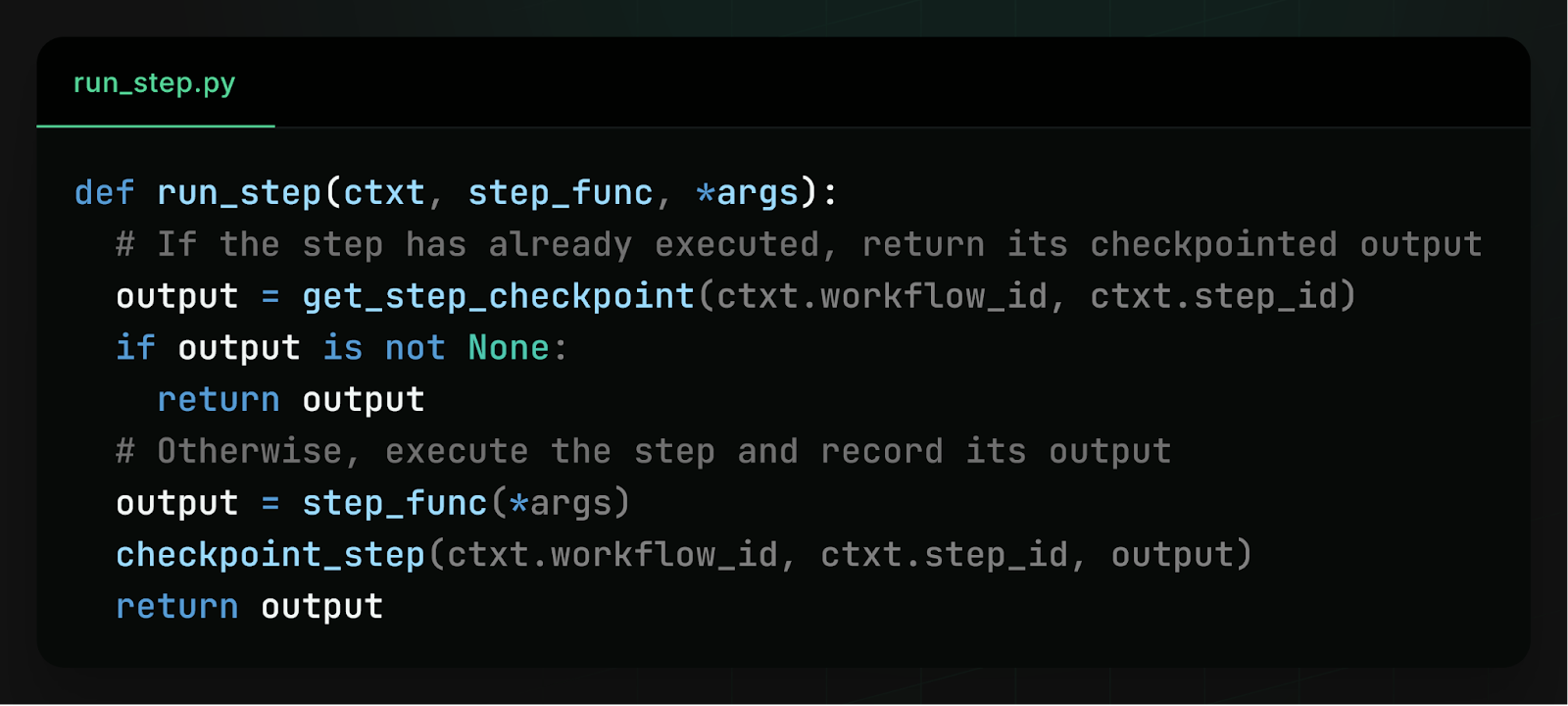
To resolve workflow duplication, we add a UNIQUE constraint to the step checkpoints table in the database, requiring that each step checkpoint must have a unique combination of workflow ID and step ID. This constraint forces workflow executions to coordinate through the database, making conflicts easy to detect.
If two servers simultaneously execute the same workflow, both begin execution from the first step that does not yet have a checkpoint. These two executions then “race” to complete the step. One execution will win the race, complete the step first, write the checkpoint to the database, and move on to the next step. The other execution will lose the race, and because of the UNIQUE constraint, will fail to write a checkpoint to the database. This slower workflow execution now knows it is a duplicate, as only a concurrent workflow execution could have written the step checkpoint. The duplicate can then safely stop executing the workflow without writing any checkpoints (it instead polls the database for and eventually returns the final workflow result), preserving the integrity of workflow history.
Cron Scheduling Without Thundering Herds
One feature that is surprisingly tricky to implement in decentralized workflows is cron scheduling. It should be possible to run a workflow on a cron schedule, where a workflow is automatically called once every 15 minutes or every day. However, without a central scheduler, we need a mechanism for ensuring the workflow is only executed once per interval across all workers.
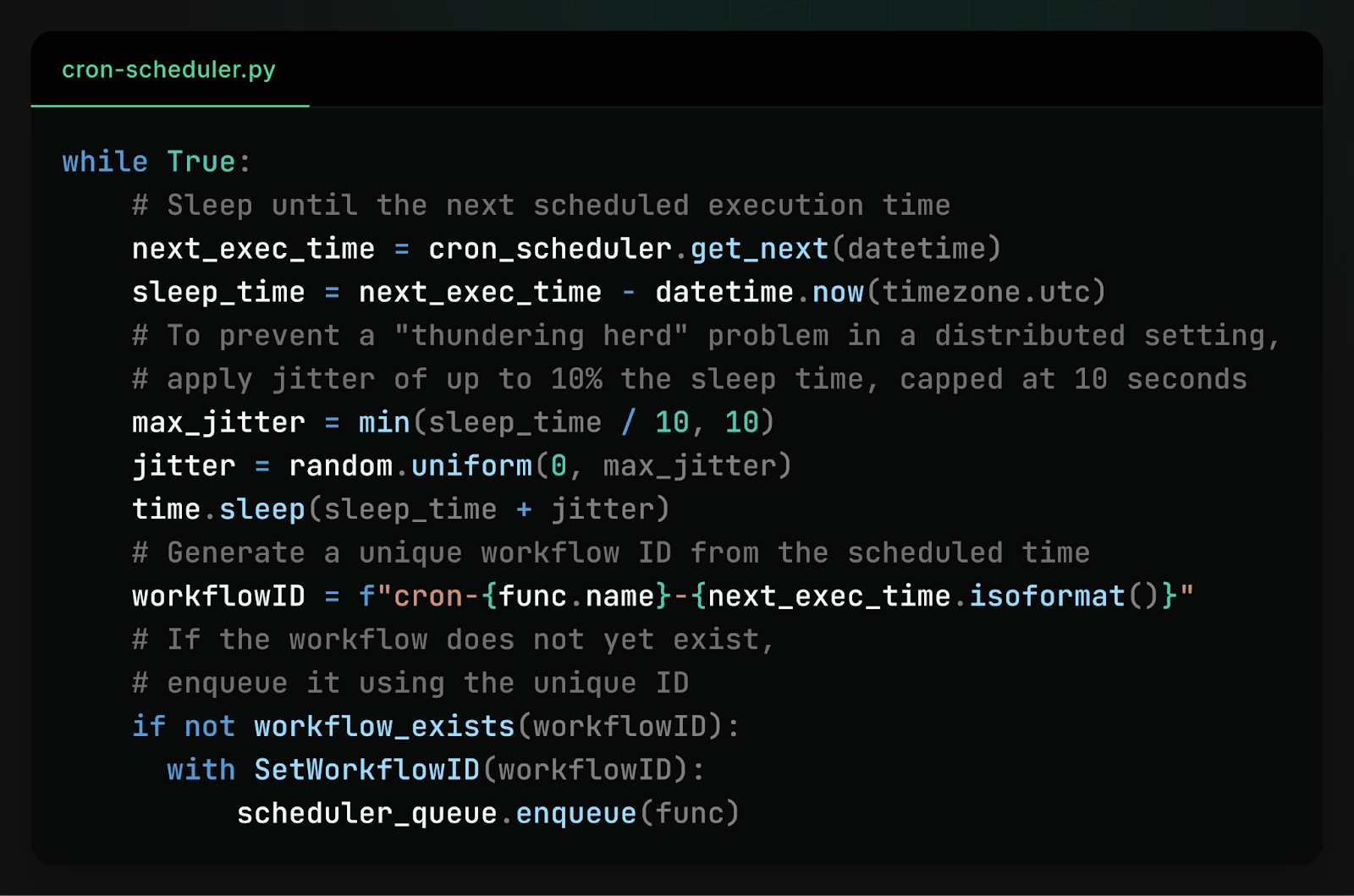
The basic solution is to have every worker run the same cron scheduler. Each time the workflow is scheduled to run, instead of running it directly, enqueue it using the scheduled time as a unique workflow ID. Every cron scheduler generates the same sequence of scheduled times, and enqueueing a workflow multiple times with the same ID is idempotent, so this guarantees the workflow is scheduled exactly once.
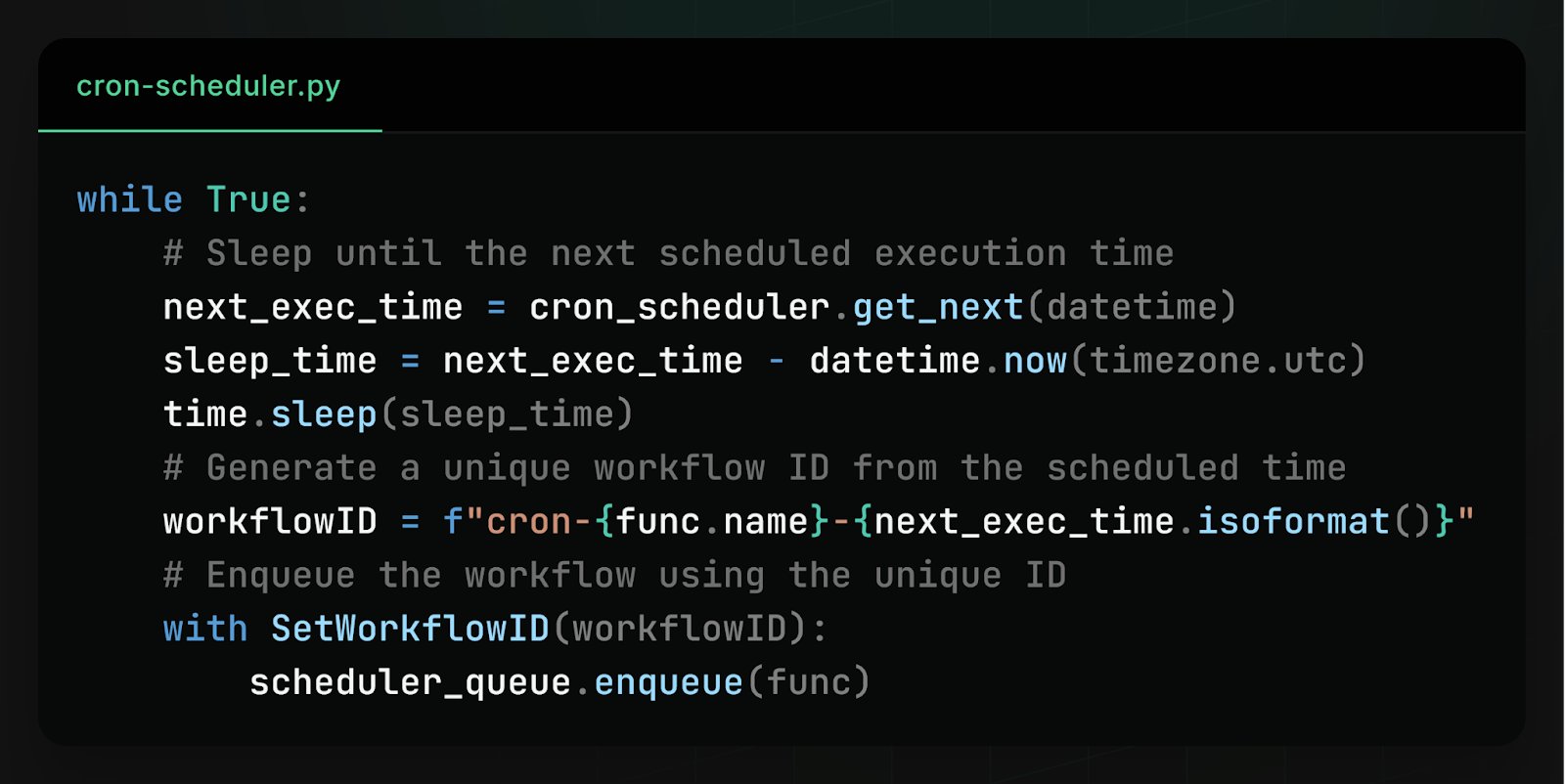
One concern with this approach is that at scale, it generates a thundering herd: spikes of high database contention when every server tries to write simultaneously to the same database table. If there are a thousand workers, this is a thousand contending database writes per cron-scheduled workflow.
To solve this problem and reduce contention, we introduce some randomness. Instead of every worker waking up at exactly the scheduled time, we add a small amount of jitter, so different workers wake up at slightly different times. We also have workers check if a workflow has already been scheduled before scheduling it–not for correctness (as scheduling is idempotent) but to replace expensive database writes with much cheaper database reads. This way, the spike in database usage is spread out over multiple seconds and converted from entirely writes to mostly reads, drastically reducing contention.
Efficient Durable Workflow Queues
It’s useful to enqueue durable workflows for later execution. However, in a decentralized system, dequeuing workflows is tricky because there’s no central orchestrator to decide which workers should execute which tasks. Instead, workers have to cooperate to dequeue different work.
Workflow queues are database-backed, so clients enqueue workflows by adding them to a queues table and workers dequeue and process the oldest enqueued workflows. The problem is that naively, all workers are concurrently and independently pulling tasks from each queue, so they all try to dequeue the same workflows. However, each workflow can only be dequeued by a single worker, so most workers will fail to find new work and have to try again. If there are enough workers, this contention creates a bottleneck in the system, limiting how rapidly tasks can be dequeued.
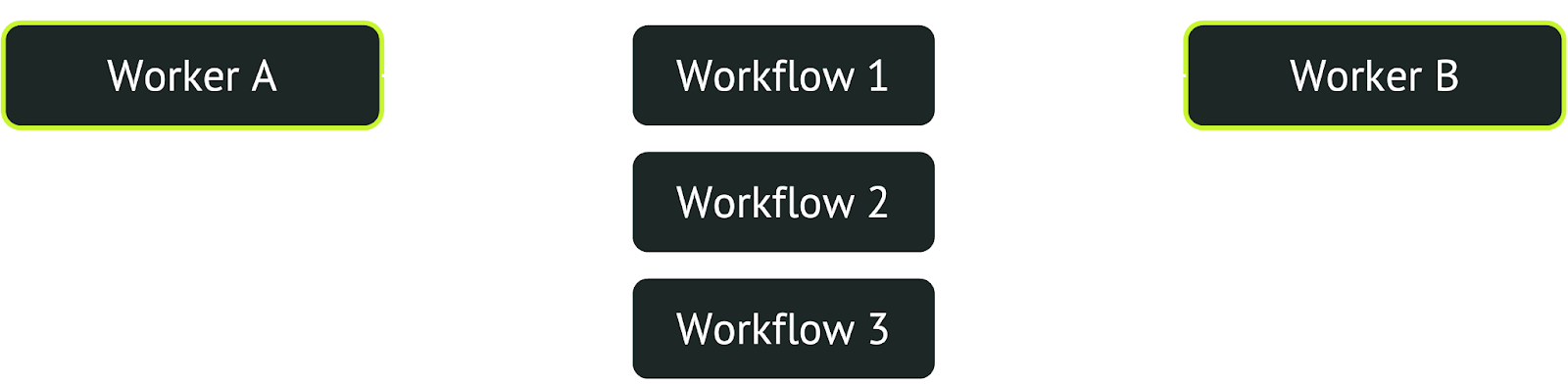
We touched on this in a previous post, but the solution is to leverage database locking clauses, essentially using database concurrency control to force workers to cooperate. Here’s an example of how to dequeue workflows using a locking clause:
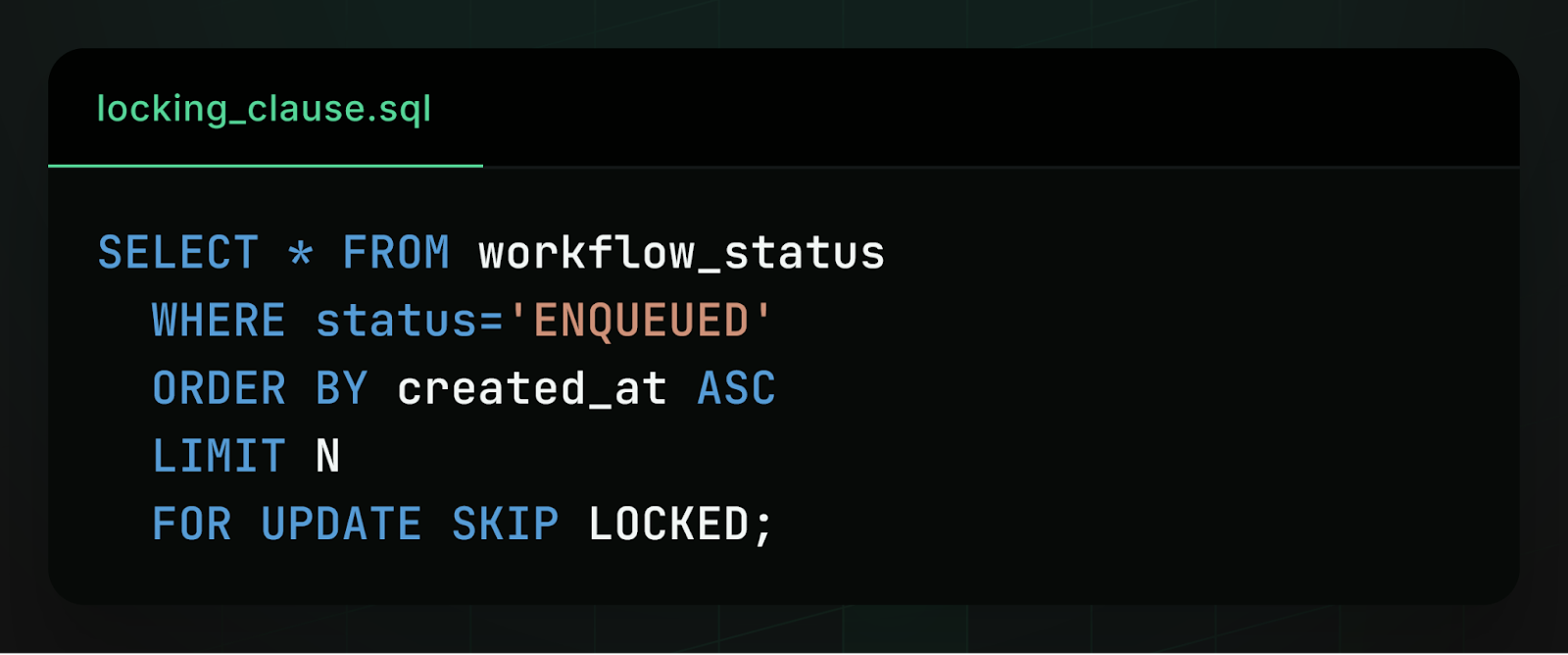
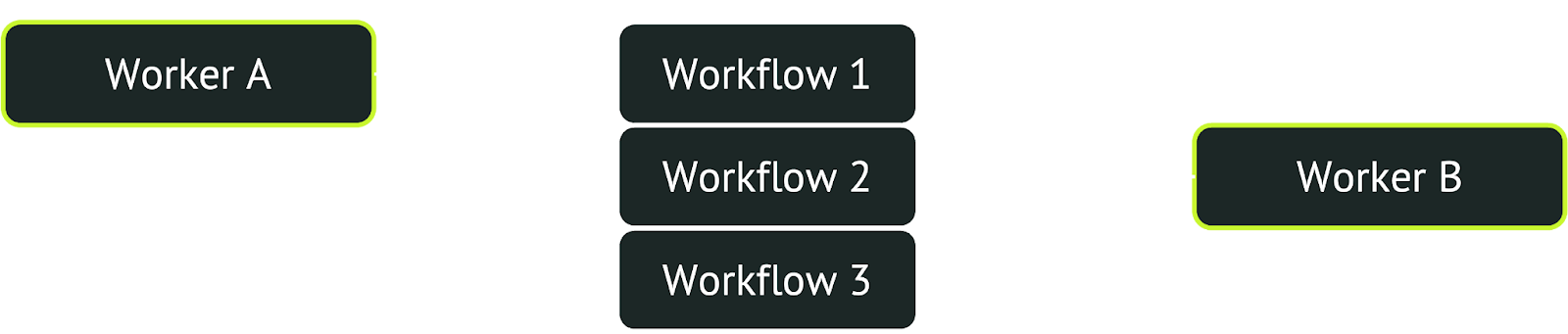
Locking clauses improve queue performance for two reasons. First, they lock selected rows so that other workers cannot also select them. Second, they skip rows that are already locked, selecting not the N oldest enqueued workflows, but the N oldest enqueued workflows that are not already locked by another worker. In other words, the database implicitly coordinates decentralized workers, so that different workers can concurrently pull new workflows without contention. One worker selects the oldest N workflows and locks them in Postgres, the second worker selects the next oldest N workflows and locks those in Postgres, and so on.
Learn More about Decentralized Workflow Orchestration Architecture
If you like hacking on complex distributed systems, we’d love to hear from you. At DBOS, our goal is to make durable workflows as lightweight and easy to work with as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc