
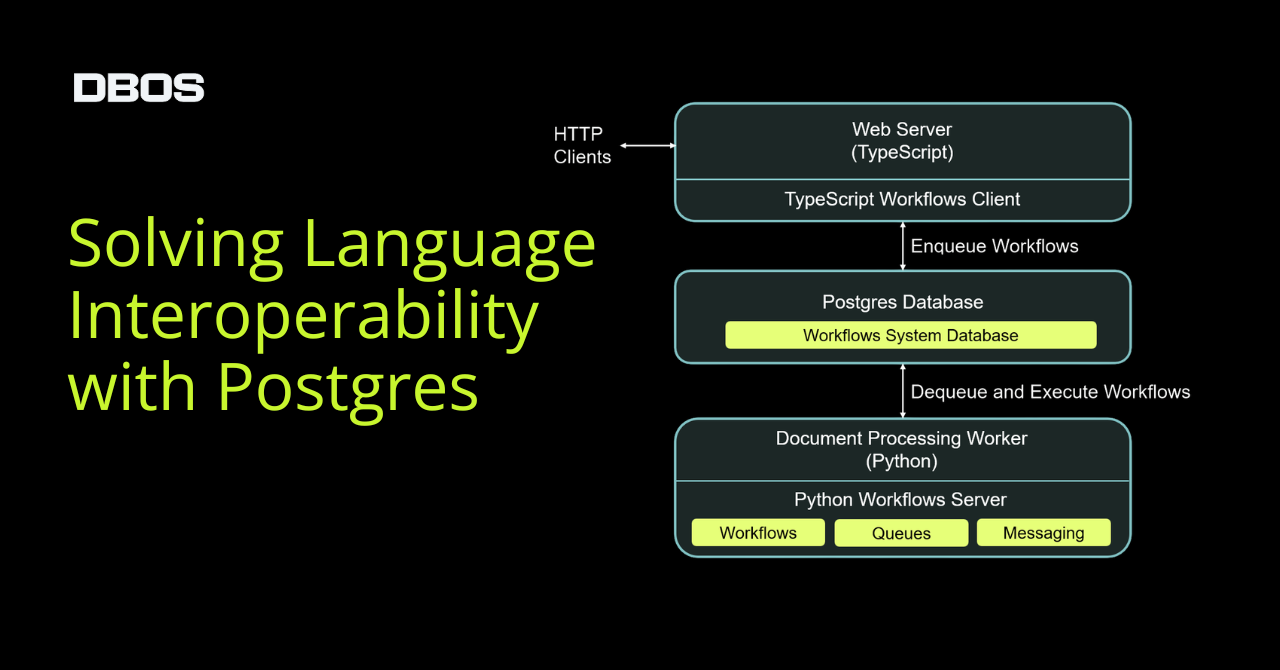
It’s not uncommon for a service written in one language to trigger or monitor tasks running in a different language. For example, you might implement a document processing pipeline in Python (because Python has a rich ecosystem for data processing), but enqueue documents and track their progress from a TypeScript web server (because TypeScript has flexible tooling for web development).
The usual solution is to add a middle layer: a message broker or an RPC service that both services talk to. This works, but it also means introducing extra infrastructure to operate and another dependency into the stack.
In a previous blog post, we explained why you should build durable workflows with Postgres. While extending Postgres-backed durable execution libraries to multiple languages, we kept coming back to a natural follow-up idea: "Applications already depend on a database (usually Postgres). Why not just use the database itself as the bridge between languages?"
In this blog post, we’ll talk about one implementation of that “bridge.” The idea is that a client in one language can connect to the system database of an application written in another language to exchange data through workflows, messages, events, and streams.
For example, here’s a diagram of how a TypeScript web server can interoperate with a document processing pipeline written in Python:

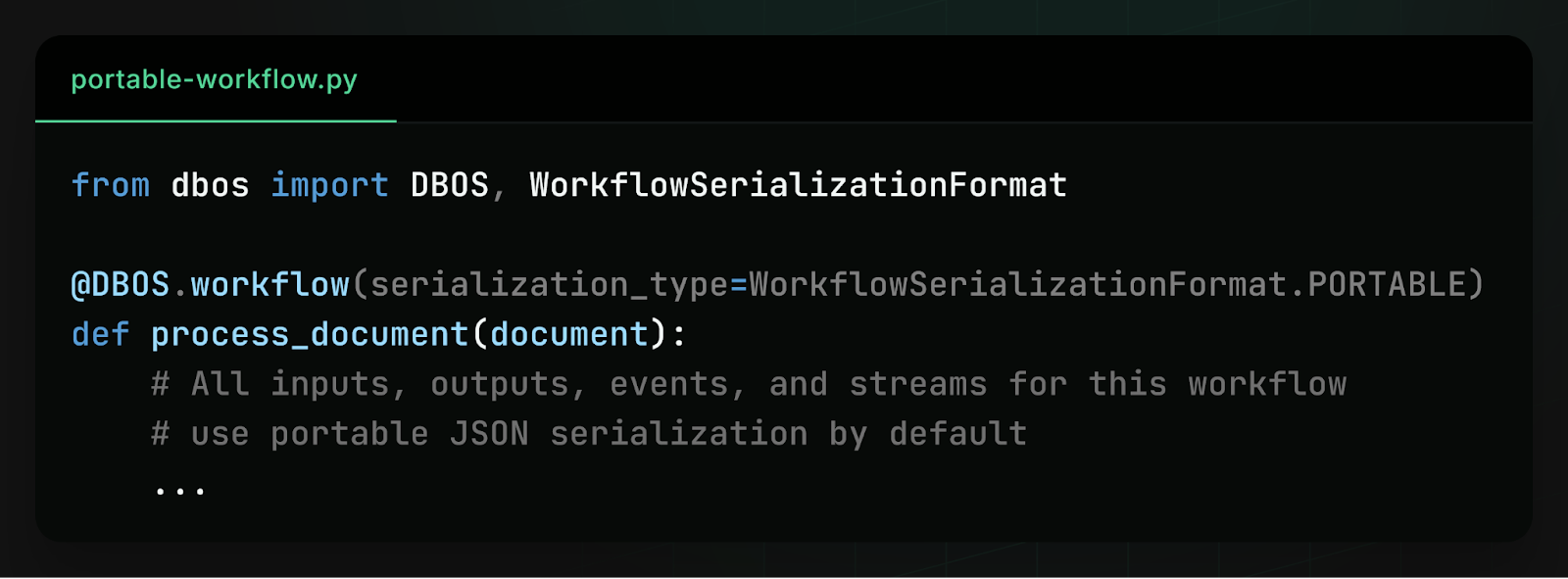
To make this work, you declare a document processing workflow in Python and mark it as "portable" across languages:
Then you can enqueue a document for processing from a TypeScript application:
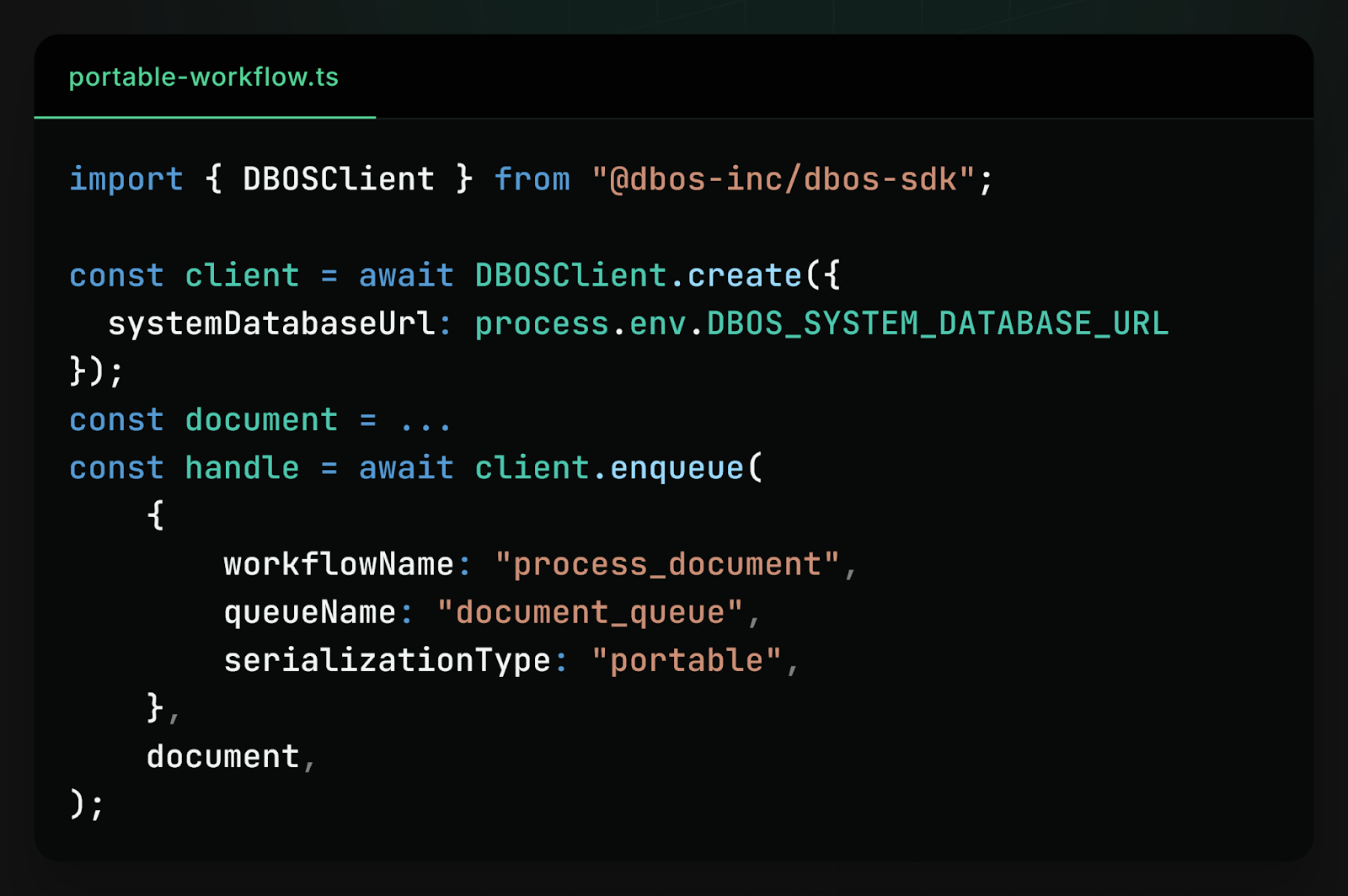
Because the system state is stored in Postgres, all languages coordinate through the same tables. This approach avoids introducing an additional orchestration service or message broker. The database already provides durability, transactions, and concurrency control.
Using Postgres as a Language-Neutral Control Plane
Workflow interoperability is possible because every implementation of the DBOS workflows library is built on the same database schema. For example, in every language a workflow is represented as an entry in the same workflow_status table. The workflow’s name is stored in a workflow_name field, its inputs in a workflow_inputs field, and so on. Here’s a simplified view of the schema:
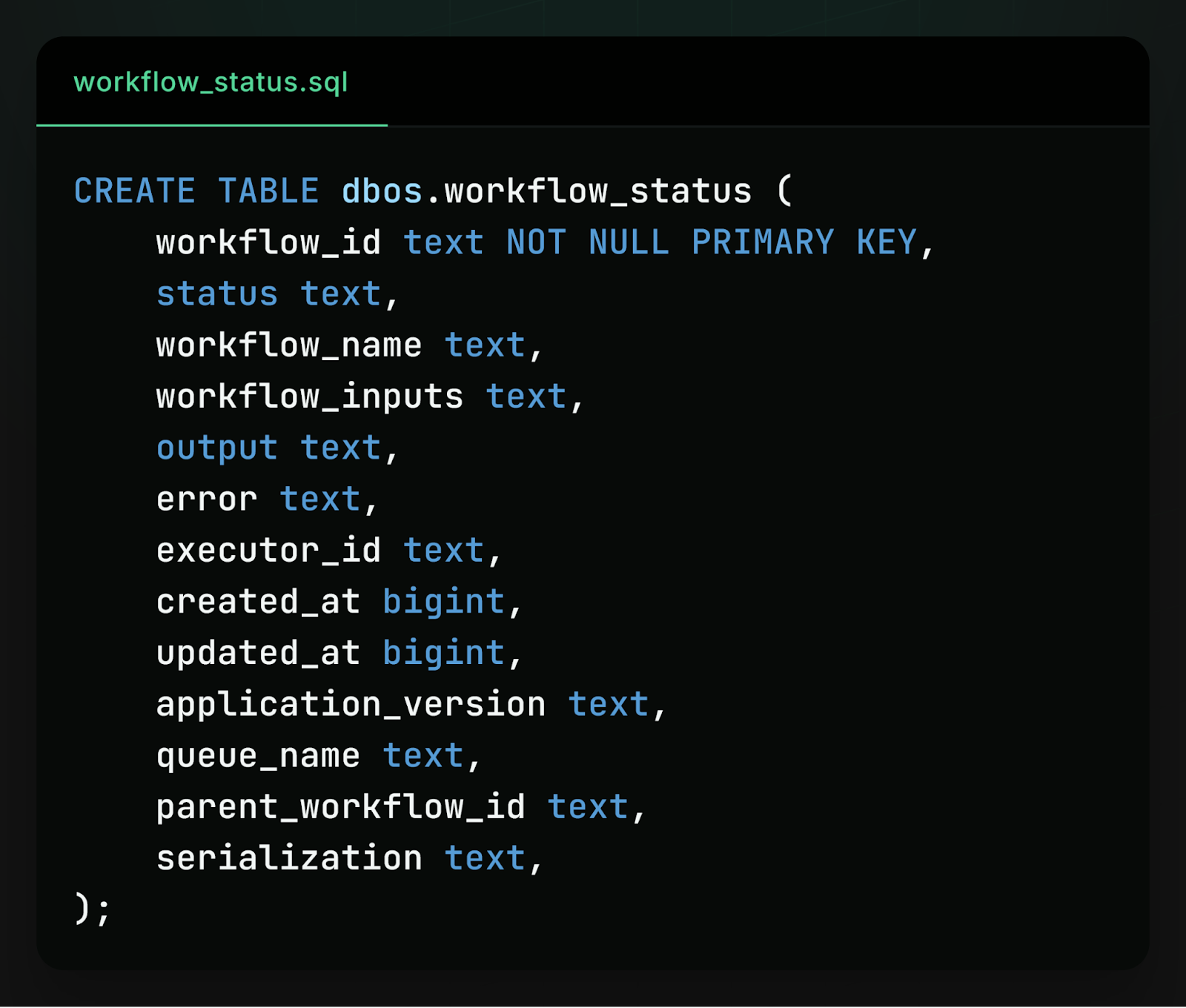
Because a workflow is represented as a database row with a schema that’s consistent across languages, a client in one language can enqueue a workflow to an application written in another language with a single INSERT statement:
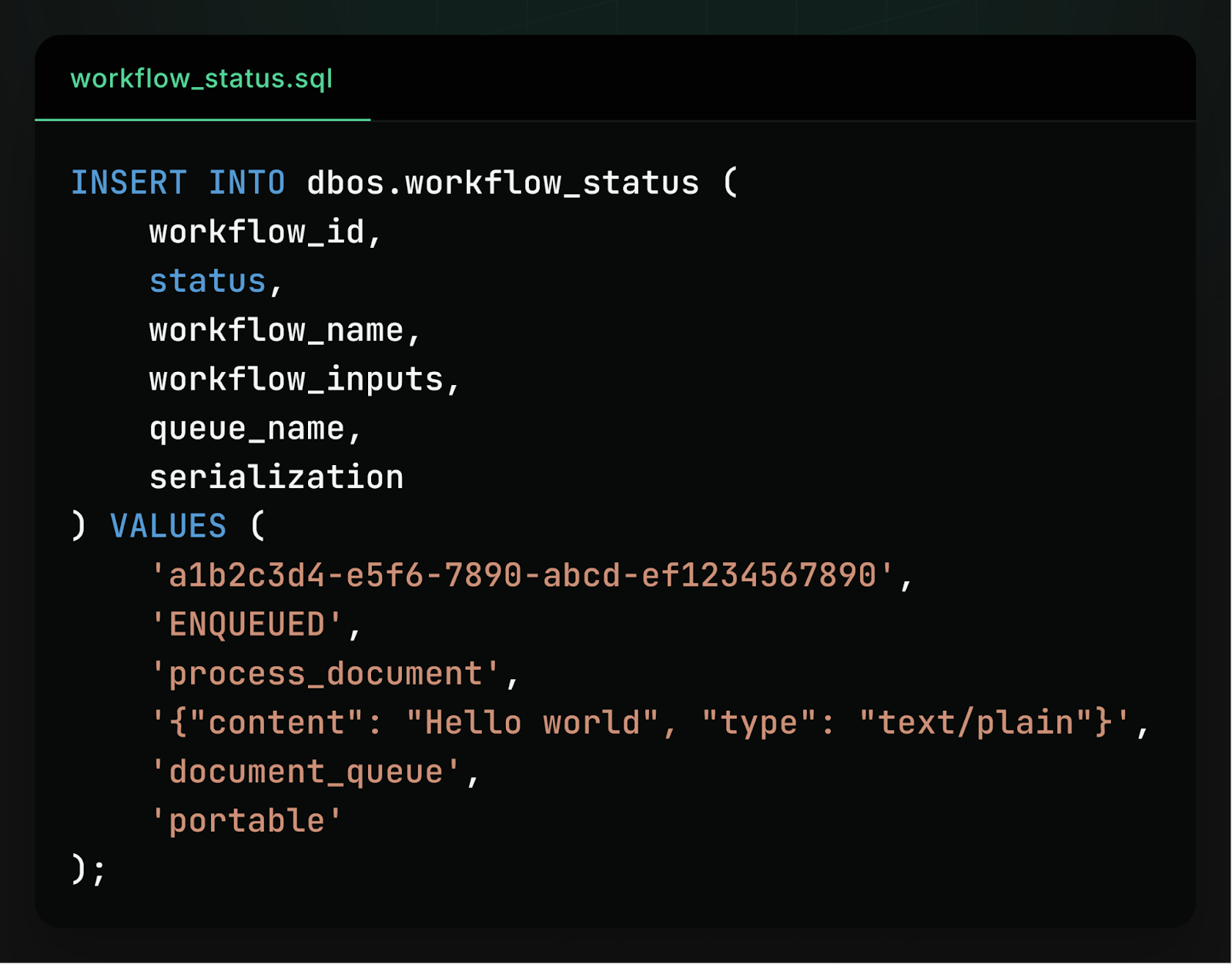
Similarly, a client in one language can check on the status (or retrieve the output) of a workflow executing in another language with a simple SELECT statement:
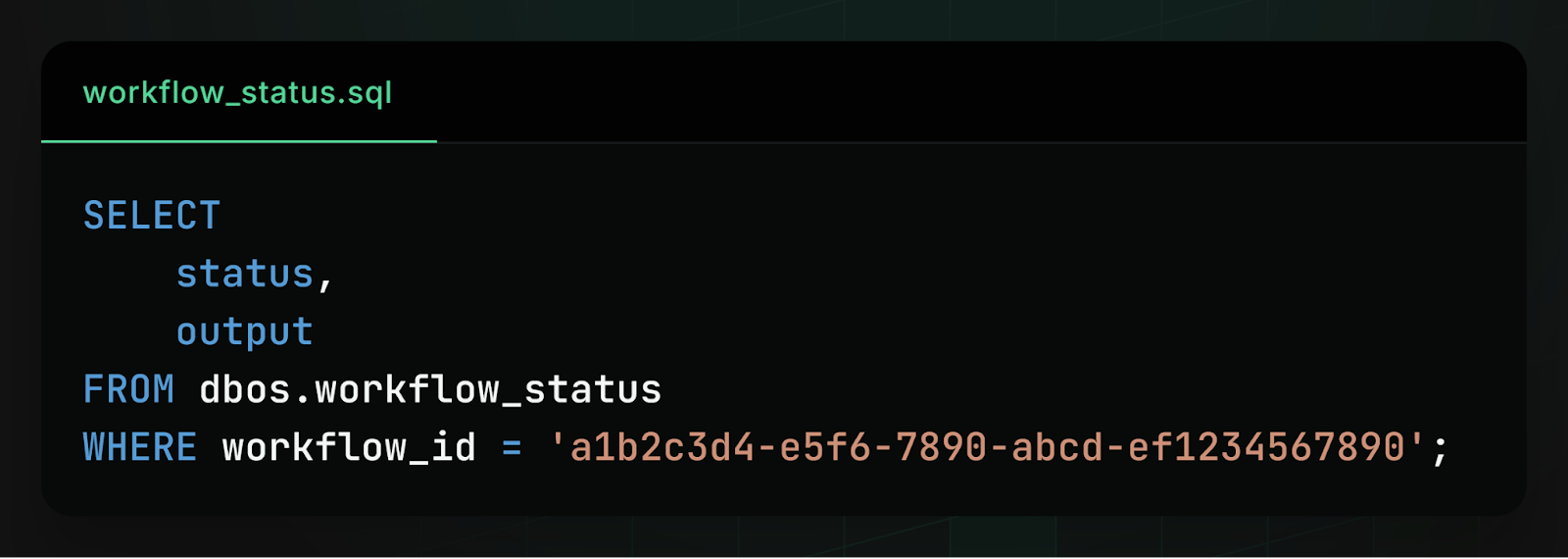
In practice, this shared schema effectively turns the database into a language-neutral control plane for workflows. Clients interact with workflows by writing and reading rows in Postgres. The application that owns the workflow simply watches the relevant tables and executes new tasks when they appear.
The Hard Part: Serializing Data Across Languages
While a shared schema makes interoperability possible, there’s another challenge in implementing it: data serialization.
To call a workflow from another language, we have to figure out how to represent its inputs, outputs, and messages in the database. By default, each language’s workflow library uses a different serialization format (pickle in Python, SuperJSON in TypeScript, etc.) chosen for their fidelity to the wide range of data structures and objects those languages support.
Because these formats are language-specific, data written in one language’s default format cannot be read in another language. For example, a Python workflow that stores its inputs in pickle produces a binary blob that TypeScript can’t deserialize.
To solve this problem, interoperable workflows use a special JSON-based serialization format that’s shared across all languages. This format supports a smaller subset of language constructs than native formats like pickle, but any DBOS application can read or write it. The supported types are:
- JSON primitives: null, booleans, numbers, and strings
- JSON arrays (ordered lists of JSON values)
- JSON objects (maps with strings as keys and JSON values)
Importantly, this special serialization format is only used for data that has to be read across languages, like workflow inputs, outputs, notifications, and messages. Intermediate data used within a workflow, like the outputs of individual steps, still use language-native serialization for full flexibility.
This design makes it easier to build portable workflows, as only data that has to be written or read from other languages needs to use the more restrictive serialization format. For example, in the document processing workflow above, its “document” input type should be JSON-serializable so TypeScript documents can be enqueued to a Python application, but the workflow can use any intermediate object types while transforming and processing documents.
Moreover, because workflows are stored and coordinated through the database, applications written in different languages can interact with the same workflows without any additional orchestration service.
Learn More
To learn more about how to operate workflows across languages, check out the documentation.
If you like making systems reliable, we’d love to hear from you. At DBOS, our goal is to make durable workflows as easy to work with as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67




